Understanding and Comparing Embedding Models for RAG and Vector Search

In the rapidly evolving landscape of artificial intelligence, embedding models have emerged as the unsung heroes powering everything from semantic search to recommendation systems. These sophisticated models transform unstructured data into numerical vectors that preserve semantic meaning, enabling machines to understand and process human language with unprecedented accuracy.
What Are Embedding Models?
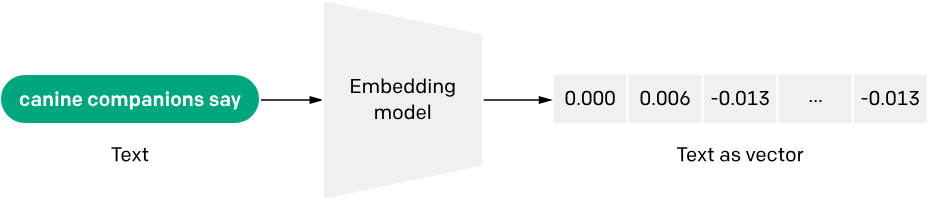
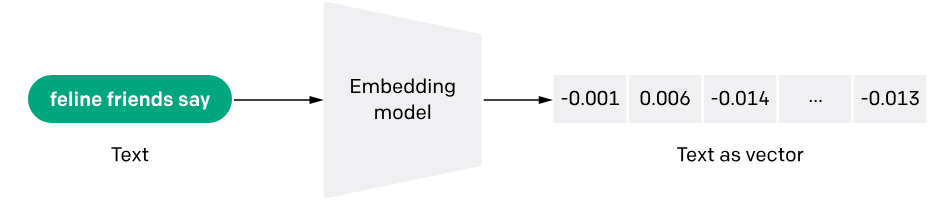
Embedding models are specialized neural networks that convert text, images, audio, or other data types into high-dimensional vector representations. Think of them as translators that convert human-readable content into a mathematical language that computers can understand and compare.
The magic lies in their ability to capture semantic relationships. For instance, the vectors for "cat" and "dog" will be positioned closer together in the vector space than either would be to "automobile," reflecting their semantic similarity as pets and animals.
Core Functions of Embedding Models
Semantic Transformation
Embedding models map words and sentences into real-valued vectors ranging from 384 to 1536 dimensions, representing "semantic similarity" as geometric distance. This mathematical representation enables powerful applications like:
- Semantic Search: Finding documents based on meaning rather than exact keyword matches
- Content Recommendation: Identifying similar items based on semantic understanding
- Cross-lingual Understanding: Bridging language barriers through shared vector spaces
Multi-Modal Support
Modern embedding models extend beyond text to support various data formats:
- Text: BERT, RoBERTa, and their variants
- Images: CLIP, Vision Transformers
- Audio: Wav2Vec, Whisper embeddings
- Code: CodeBERT, GraphCodeBERT
Dimensional Compression
These models compress the complexity of original data into lower-dimensional spaces (typically 768 dimensions) while preserving essential semantic information.
Key Embedding Models Comparison
| Model Name | Provider | Dimensions | Multilingual | Deployment | Strengths |
|---|---|---|---|---|---|
paraphrase-multilingual-mpnet-base-v2 |
SBERT | 768 | Yes | Local/Open-source | Strong multilingual, good in RAG |
text-embedding-3-large |
OpenAI | 3072 | Yes | Cloud API | Best performance in benchmarks |
text-embedding-ada-002 |
OpenAI (used in Azure AI Search) | 1536 | Moderate | Azure / OpenAI API | Efficient, widely supported |
all-MiniLM-L6-v2 |
SBERT | 384 | Yes | Local | Lightweight, fast |
multilingual-e5-large |
Hugging Face / Microsoft | 1024 | Yes | Local / HF Hub | Balanced multilingual encoder |
1. sentence-transformers/paraphrase-multilingual-mpnet-base-v2
Specifications:
- Dimensions: 768
- Languages: 50+ languages supported
- Model Size: ~420MB
- Training: Trained on paraphrase data across multiple languages
Strengths:
- Excellent multilingual performance
- Strong semantic similarity detection
- Good balance between performance and computational efficiency
- Proven track record in production environments
Use Cases:
- International applications requiring multilingual support
- Cross-lingual semantic search
- Global customer support systems
- Academic research across languages
Real-world Example:
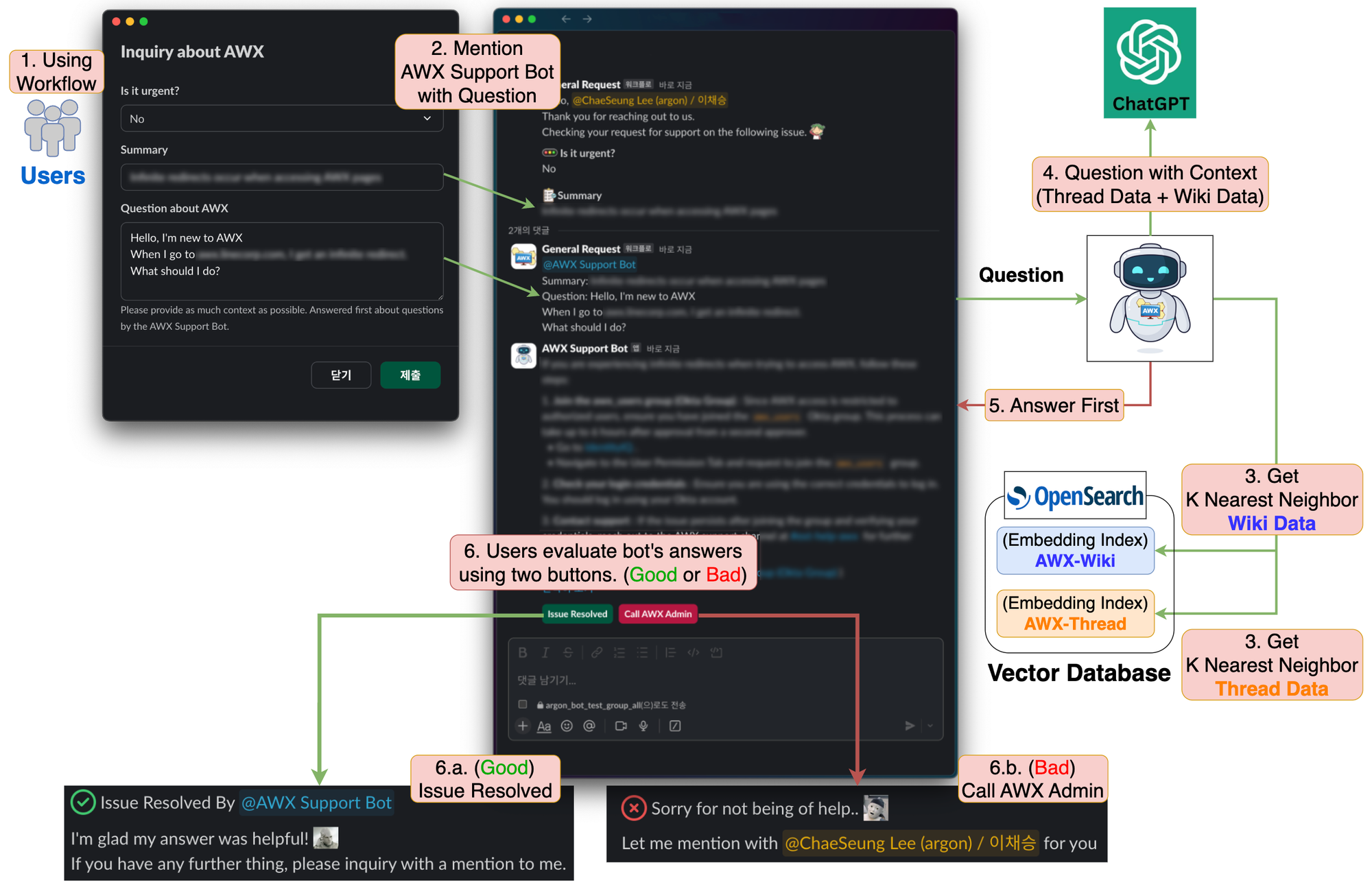
LINE Corporation successfully implemented this model in their AWX support bot, handling inquiries in multiple languages from their international workforce. The model's ability to understand semantic similarity across languages enabled effective automated responses to common technical questions.
2. OpenAI's text-embedding-3-large
Specifications:
- Dimensions: 3072 (configurable down to 256)
- Languages: Strong multilingual support
- API-based: No local deployment
- Training: Large-scale web data
Strengths:
- State-of-the-art performance on benchmarks
- Flexible dimensionality
- Consistent API updates and improvements
- Enterprise-grade reliability
Limitations:
- Requires internet connectivity
- Ongoing API costs
- Data privacy considerations
- Rate limiting constraints
Ideal For:
- Applications requiring cutting-edge performance
- Prototyping and experimentation
- Companies comfortable with cloud-based AI services
Sample Code: OpenAI text-embedding-3-large
from openai import OpenAI
client = OpenAI(api_key="YOUR_API_KEY")
response = client.embeddings.create(
model="text-embedding-3-large",
input="What is Retrieval-Augmented Generation?"
)
embedding = response.data[0].embedding
Sample Code: Azure AI Search with text-embedding-ada-002
import openai
openai.api_key = "YOUR_AZURE_API_KEY"
openai.api_base = "<https://YOUR-RESOURCE-NAME.openai.azure.com>"
openai.api_type = "azure"
openai.api_version = "2023-05-15"
response = openai.Embedding.create(
engine="text-embedding-ada-002",
input="Azure AI Search embedding demo"
)
embedding = response['data'][0]['embedding']
3. SentenceTransformers Ecosystem
Popular Models:
all-MiniLM-L6-v2: Lightweight, fast inferenceall-mpnet-base-v2: Balanced performancemulti-qa-mpnet-base-dot-v1: Optimized for Q&A
Advantages:
- Open-source flexibility
- Local deployment capability
- Extensive model variety
- Active community support
- Custom fine-tuning options
Sample Code: SentenceTransformers paraphrase-multilingual-mpnet-base-v2
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('paraphrase-multilingual-mpnet-base-v2')
embedding = model.encode("Semantic similarity across languages")
Embedding Model Selection Criteria
1. Dimensionality Considerations
- 384 dimensions: Lightweight applications, mobile deployment
- 768 dimensions: Balanced performance and efficiency
- 1536+ dimensions: Maximum accuracy for critical applications
2. Domain Specialization
- General Purpose: text-embedding-ada-002, all-mpnet-base-v2
- Medical: BioBERT, ClinicalBERT
- Legal: LegalBERT
- Scientific: SciBERT
- Multilingual: paraphrase-multilingual-mpnet-base-v2, multilingual-e5
3. Performance Metrics
- MTEB Benchmark: Comprehensive evaluation across multiple tasks
- Latency: Query processing time
- Memory Usage: Model size and RAM requirements
- Throughput: Requests per second capability
Vector Database Integration
Embedding models work hand-in-hand with vector databases to create powerful search and retrieval systems:
Popular Vector Databases
- Cloud Solutions: Pinecone, Weaviate, Qdrant Cloud
- Self-hosted: Chroma, Milvus, OpenSearch
- Enterprise: Elasticsearch with vector search
Optimization Techniques
- ANN (Approximate Nearest Neighbor): Trading slight accuracy for massive speed improvements
- Hybrid Search: Combining metadata filtering with vector search
- Re-ranking: Post-processing results for improved relevance
Real-World Implementation: RAG Systems
The combination of embedding models and vector databases forms the foundation of Retrieval-Augmented Generation (RAG) systems:
Architecture Overview
- Data Ingestion: Process documents, PDFs, and other content
- Embedding Generation: Convert content to vectors using chosen model
- Vector Storage: Index embeddings in vector database
- Query Processing: Convert user queries to embeddings
- Similarity Search: Find relevant content chunks
- LLM Integration: Inject retrieved context into language model
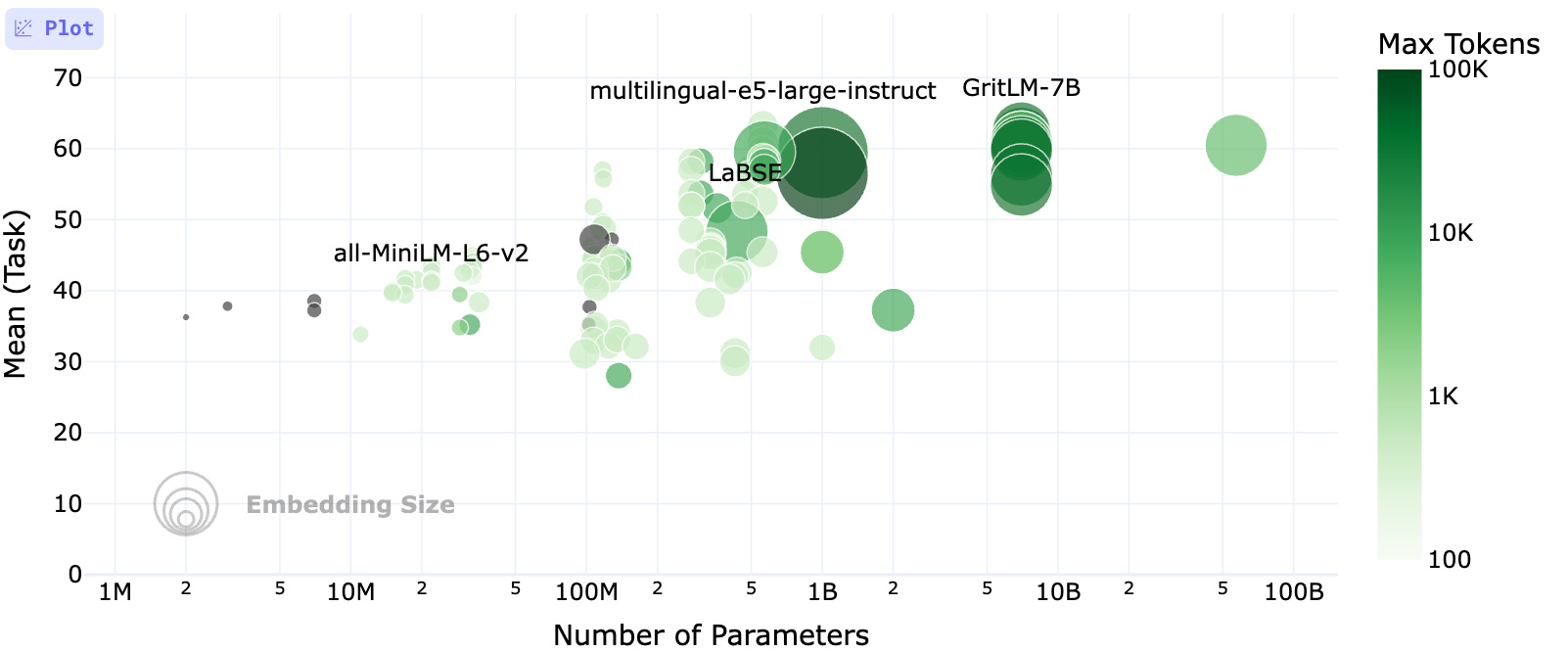
Performance Benchmarks
Hugging Face MTEB (Massive Text Embedding Benchmark) Leaderboard offers comprehensive benchmarks of 264 embedding models. The table below presents performance benchmarks for several widely used embeding models. These metrics provide a holistic view of how models perform across diverse NLP tasks, including semantic similarity (STS), retrieval, and multilingual applications.
| Model | Mean (All Tasks) | Retrieval | STS | Dimensions | Params | Memory (MB) | Max Tokens | Zero-shot |
|---|---|---|---|---|---|---|---|---|
| multilingual-e5-large-instruct | 63.22 | 62.61 | 76.81 | 1024 | 560M | 1068 | 514 | 99% |
| text-embedding-3-large | 58.93 | 63.89 | 71.68 | 3072 | Unknown | Unknown | 8191 | NA |
| paraphrase-multilingual-mpnet-base-v2 | 51.98 | 53.37 | 69.66 | 768 | 278M | 1061 | 512 | 100% |
| all-mpnet-base-v2 | 42.33 | 42.23 | 57.60 | 768 | 109M | 418 | 384 | 100% |
| GIST-all-MiniLM-L6-v2 | 42.70 | 41.45 | 61.52 | 384 | 22M | 87 | 512 | 96% |
Key Insights:
multilingual-e5-large-instructachieves the highest average score and leads in STS tasks, making it ideal for multilingual and semantic-heavy use cases.text-embedding-3-largeexcels in retrieval and balances well across tasks with support for up to 8191 tokens.paraphrase-multilingual-mpnet-base-v2remains a reliable, open-source option with strong multilingual support and efficiency.GIST-all-MiniLM-L6-v2is extremely lightweight, offering quick inference with decent performance for smaller applications.
Best Practices for Implementation
1. Model Selection Strategy
- Start with general-purpose models for prototyping
- Consider domain-specific models for specialized use cases
- Factor in deployment constraints (local vs. cloud)
- Evaluate multilingual requirements early
2. Data Preprocessing
- Clean and normalize text input
- Handle special characters and encoding issues
- Consider chunking strategies for long documents
- Implement proper error handling
3. Performance Optimization
- Batch processing for multiple embeddings
- Caching for frequently accessed embeddings
- GPU acceleration when available
- Monitor and optimize vector database performance
4. Quality Assurance
- Implement similarity threshold tuning
- Regular evaluation against ground truth data
- A/B testing for model comparisons
- User feedback integration
Future Trends and Considerations
Emerging Technologies
- Multimodal Models: CLIP-style architectures for text-image understanding
- Sparse Embeddings: Models like SPLADE for interpretable retrieval
- Adaptive Embeddings: Context-aware vector representations
- Smaller Models: Distilled versions for edge deployment
Industry Adoption
Organizations across industries are leveraging embedding models for:
- Healthcare: Medical literature search and diagnosis support
- Finance: Document analysis and risk assessment
- Legal: Contract analysis and case law research
- E-commerce: Product recommendation and search enhancement
Conclusion
Embedding models represent a fundamental shift in how we process and understand unstructured data. Whether you choose the multilingual capabilities of paraphrase-multilingual-mpnet-base-v2, the cutting-edge performance of text-embedding-3-large, or the flexibility of the SentenceTransformers ecosystem, the key is matching your model choice to your specific requirements.
The combination of robust embedding models, efficient vector databases, and thoughtful system design creates opportunities for organizations to transform how they handle information retrieval, customer support, and knowledge management. The question isn't whether to adopt embedding technology, but how quickly you can integrate it effectively into your existing systems.