Training Basic Two Layer Network with Numpy
In this post, we develop a two-layer network in order to perform classification in MNIST dataset and train it. There are mainly two parts…

In this post, we develop a two-layer network in order to perform classification in MNIST dataset and train it. There are mainly two parts we will create: building a two layer network and training the network.
You need to visit Github for imports, auxiliary functions and MNIST dataset.
Two Layer Network
Let’s briefly check the full code of two layer network layer and divide it into functions to understand them.
Initialization
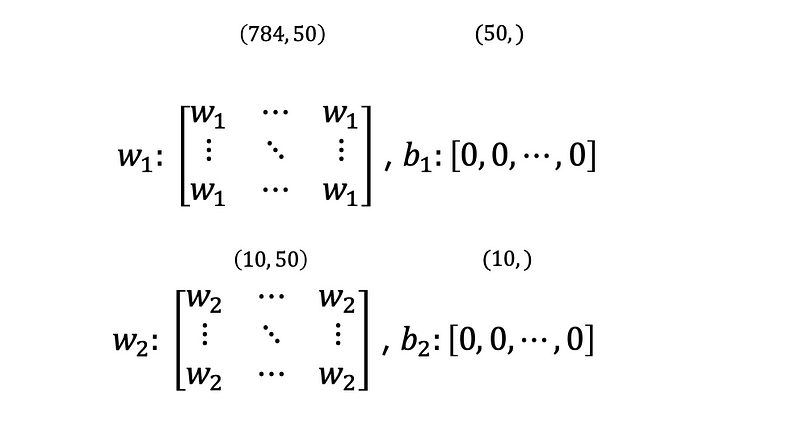
For initialization, We need to define the size of input data, output data, hidden nodes and so on. We also prepare two types of parameter: weights and biases. Since we will setinput_size=784, hidden_size=50 and output_size=10, the shape of the weights and biases is:
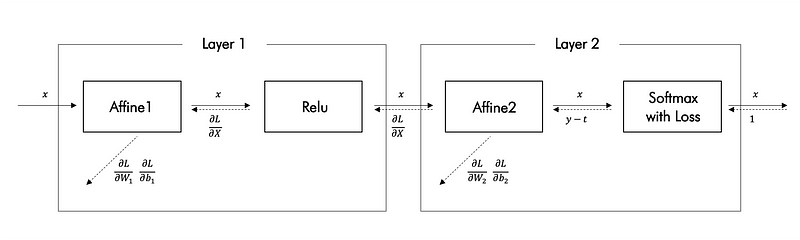
There are 4 layers that are Affine 1, Relu, Affine 2 and Softmax with Loss. You can find source codes here and explanation of them from my posts: Affine, Relu, Softmax with Loss.

Prediction
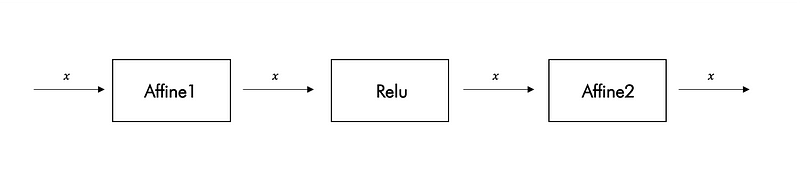
The predict fucntion simply makes a forward pass for the input x, and then get the maximum of the scores that was found.
Loss
Before we compute the loss, we need to first perform a forward pass. As we defined the last layer is the softmax and loss layer, we will be using the cross-entropy loss.
Accuracy
Using argmax, we choose the highest probability among all the probability and y is its index. If predicted label values(y) find the true label valuse, we can sum of them to calculate the accuracy.
Gradient

The gradients can be calculated by reversing layers. After doing backward pass for softmax with loss layer, the dout values back propagate across the network.
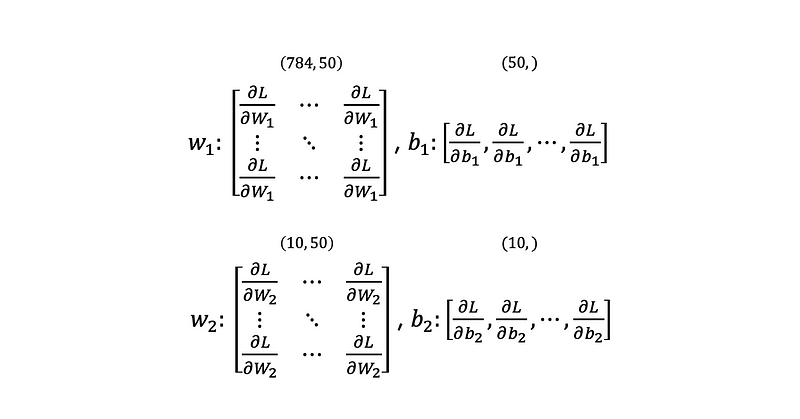
And we need to save derivatives of the weights and biases. The shape of them will be below:
Training
Firstly, we define train dataset and test dataset and set parameteres including the number of iteration, batch size and learning rate.
We make a batch mask that is used to create a random minibatch of training data and labels, then we store them in X_batch and Y_batch respectively. We update our parameters in our network and loss vlaues are appended to train_loss_list. The accuracy values are also appended to lists while training.
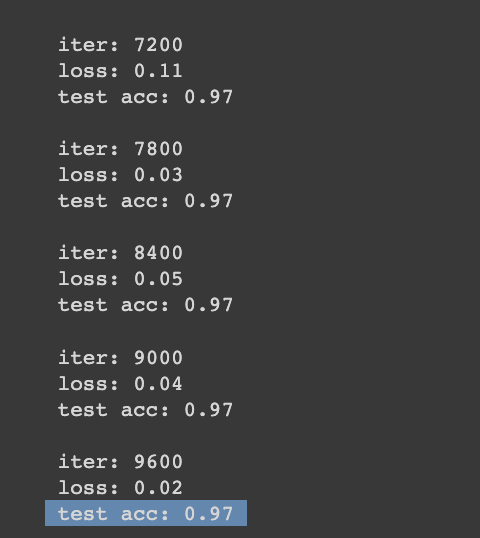
The final test accuracy is 0.97.
Thank you for reading =)