The Rise of On-Device AI: Comparing SLMs on NPUs and Copilot+ PCs
We're now witnessing the emergence of powerful on-device AI capabilities that promise to revolutionize how we interact with our computers. At the forefront of this transformation are SLMs running on NPUs, with Microsoft's Copilot+ PCs leading the charge into this new era.

The landscape of artificial intelligence is undergoing a dramatic shift. While cloud-based AI has dominated the past decade, we're now witnessing the emergence of powerful on-device AI capabilities that promise to revolutionize how we interact with our computers. At the forefront of this transformation are Small Language Models (SLMs) running on Neural Processing Units (NPUs), with Microsoft's Copilot+ PCs leading the charge into this new era.
The Evolution from Cloud to Edge
For years, AI applications have relied heavily on cloud computing, sending user data to remote servers for processing. This approach, while powerful, comes with significant limitations including latency, privacy concerns, internet dependency, and ongoing operational costs. The shift toward on-device AI represents a fundamental change in how we think about artificial intelligence deployment.
On-device AI processing offers compelling advantages that address many of the cloud-based limitations. Users experience dramatically reduced latency since computations happen locally, enhanced privacy as sensitive data never leaves the device, improved reliability with offline functionality, and reduced long-term costs by eliminating the need for continuous cloud API calls.
Understanding Small Language Models (SLMs)
Small Language Models represent a new category of AI models specifically designed for edge deployment. Unlike their massive cloud-based counterparts that contain hundreds of billions of parameters, SLMs typically range from 1 billion to 13 billion parameters, making them suitable for local execution while still maintaining impressive capabilities.
These models achieve their efficiency through several innovative approaches. Advanced training techniques like knowledge distillation allow smaller models to learn from larger teacher models, capturing much of their knowledge in a more compact form. Quantization reduces model size by using lower precision numbers without significantly impacting performance. Specialized architectures are optimized for specific tasks rather than trying to be general-purpose solutions for everything.
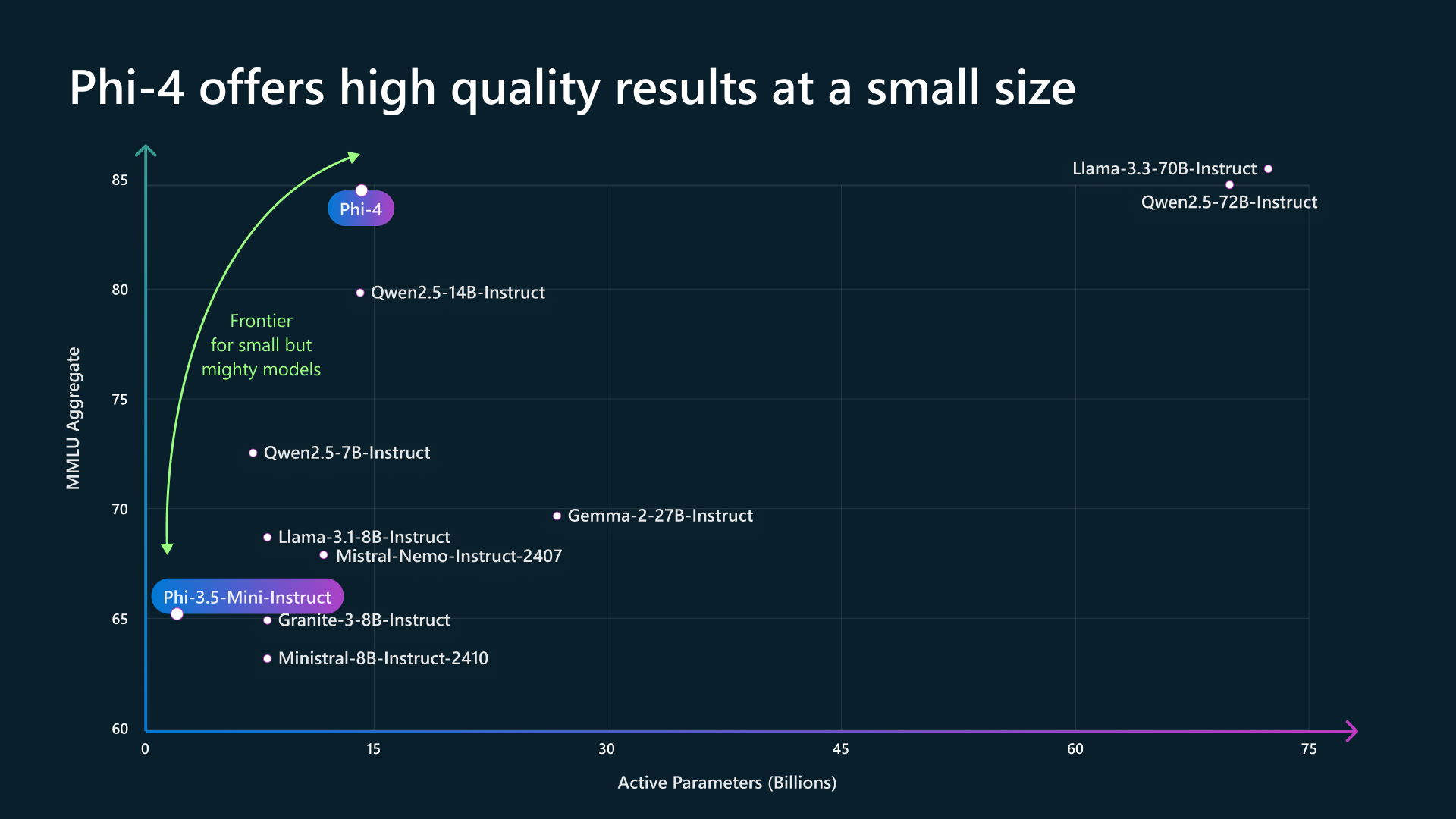
Popular SLMs making waves in the industry include Microsoft's Phi series, which offers remarkable performance despite their compact size. Microsoft’s Phi-4 series represents a significant advancement in small language models (SLMs), offering powerful on-device AI capabilities. These models are designed to operate efficiently on devices equipped with Neural Processing Units (NPUs), such as Microsoft’s Copilot+ PCs.

Phi-4 Series Overview
- Phi-4: A 14-billion-parameter model optimized for complex reasoning tasks. It utilizes high-quality synthetic data and advanced training techniques to achieve performance comparable to larger models on benchmarks like MMLU and HumanEval .
- Phi-4-Reasoning & Phi-4-Reasoning-Plus: These variants are fine-tuned for enhanced reasoning capabilities. Phi-4-Reasoning-Plus incorporates reinforcement learning to process more tokens, delivering higher accuracy, particularly in mathematical and scientific reasoning tasks .
- Phi-4-Mini: A compact 3.8-billion-parameter model designed for efficiency. It features a 200,000-token vocabulary and grouped-query attention, making it suitable for tasks like instruction following and function calling .
- Phi-4-Mini-Reasoning: An enhanced version of Phi-4-Mini, optimized for mathematical reasoning. It employs a systematic training recipe, including supervised fine-tuning and reinforcement learning, to achieve strong performance on math benchmarks .
- Phi-4-Multimodal: This 5.6-billion-parameter model supports text, audio, and vision inputs, enabling natural and context-aware interactions. It’s designed for multimodal tasks like speech recognition, translation, and image analysis .
Integration with Copilot+ PCs
Microsoft’s Copilot+ PCs leverage these Phi-4 models to deliver advanced on-device AI experiences. Features like real-time transcription, intelligent writing assistance, and AI-powered search are powered by these models, ensuring low latency and enhanced privacy without relying on cloud services .
The Phi-4 series exemplifies the potential of small language models in delivering robust AI capabilities directly on devices, marking a significant shift towards more private, efficient, and accessible artificial intelligence.
Google's Gemma models offer another compelling option with Gemma-2B and Gemma-7B providing different performance-efficiency trade-offs. Apple's on-device models power features like Siri and text processing, though specific architectural details remain proprietary. Meta's Llama 2 7B model, while not specifically designed as an SLM, represents the lower bound of what's possible with traditional architectures.
Neural Processing Units: The Hardware Revolution
Neural Processing Units represent specialized silicon designed specifically for AI workloads. Unlike general-purpose CPUs or even GPUs, NPUs are architected to excel at the matrix operations and parallel processing patterns common in neural networks.
The key differences between Neural Processing Units (NPUs) and Graphics Processing Units (GPUs) in the context of AI workloads can be described below:
|
Feature |
NPU (Neural Processing Unit) |
GPU (Graphics Processing Unit) |
|---|---|---|
|
Primary Use Case |
Optimized for AI inference tasks, especially on edge devices and mobile platforms. |
Designed for parallel processing, excelling in graphics rendering and AI training workloads. |
|
Architecture |
Specialized for matrix operations and neural network computations with dedicated AI accelerators. |
General-purpose parallel processors with thousands of cores suitable for a wide range of computations. |
|
Performance (TOPS) |
Typically offers high TOPS (Tera Operations Per Second) for AI tasks with lower power consumption. |
Provides high computational power, with some models achieving significant TOPS, but often with higher power usage. |
|
Energy Efficiency |
Highly energy-efficient, making them ideal for battery-powered devices and continuous AI tasks. |
Less energy-efficient compared to NPUs, leading to higher power consumption and heat generation. |
|
Latency |
Low latency due to on-device processing, beneficial for real-time AI applications. |
Higher latency when used for AI inference, especially if data transfer between CPU and GPU is involved. |
|
Integration |
Often integrated into SoCs (System on Chips) for smartphones and embedded devices. |
Can be discrete or integrated; discrete GPUs are common in desktops and servers, while integrated GPUs are in SoCs. |
|
Flexibility |
Tailored for specific AI tasks; less flexible for general-purpose computing. |
Highly flexible, capable of handling a variety of tasks beyond AI, including gaming and scientific simulations. |
|
Development Ecosystem |
Emerging ecosystem with growing support in AI frameworks and libraries. |
Mature ecosystem with extensive support across various development tools and AI frameworks. |
Modern NPUs deliver several key advantages over traditional processors. They provide exceptional energy efficiency, often delivering 10-100x better performance per watt compared to CPUs for AI tasks. Their parallel architecture excels at the simultaneous operations required by neural networks. Optimized memory hierarchies reduce data movement overhead, while specialized instruction sets are designed specifically for AI operations like convolutions and attention mechanisms.
Leading NPU implementations include Qualcomm's Hexagon NPUs found in Snapdragon processors, offering up to 45 TOPS (Trillion Operations Per Second) in mobile devices. Intel's AI Boost technology in their latest processors provides integrated NPU functionality for laptops and desktops. AMD's XDNA architecture powers their NPU implementations, while Apple's Neural Engine has been pioneering on-device AI in mobile devices for years. ARM's Ethos-N series provides NPU IP for various chip manufacturers.
Microsoft Copilot+ PCs: Defining the Standard

Microsoft's Copilot+ PC initiative represents the company's vision for AI-powered personal computing. These systems integrate powerful NPUs capable of at least 40 TOPS of AI performance, enabling sophisticated on-device AI experiences that were previously impossible.
The Copilot+ PC ecosystem encompasses several key components. Hardware requirements include NPUs with minimum 40 TOPS performance, at least 16GB of unified memory, and fast storage solutions. Software integration features Windows 11 with enhanced AI capabilities, the Copilot assistant deeply integrated into the OS, and AI-powered features across Microsoft's application suite. Development tools include the Windows AI platform for developers and optimized runtimes for popular AI frameworks.
Key features enabled by Copilot+ PCs demonstrate the potential of on-device AI. Windows Studio Effects provide real-time background blur, eye contact correction, and voice enhancement without cloud processing. Live Captions offer real-time transcription and translation for audio content. AI-powered search enables natural language queries across files and applications. Creative tools leverage AI for image generation, text summarization, and content enhancement.
Performance Comparisons: NPUs vs Traditional Processors
When evaluating on-device AI performance, the differences between NPUs and traditional processors become stark. Benchmark comparisons reveal significant advantages for specialized AI hardware across multiple dimensions.
In terms of raw performance, NPUs typically deliver 5-20x better throughput for AI workloads compared to CPUs, while maintaining competitive performance against GPUs in many scenarios. Energy efficiency shows even more dramatic differences, with NPUs often consuming 10-100x less power than equivalent CPU or GPU implementations for the same AI tasks.
Real-world performance metrics demonstrate these advantages clearly. Language model inference on a modern NPU can process 20-50 tokens per second while consuming only 2-5 watts of power. The same task on a CPU might achieve 5-15 tokens per second while consuming 15-30 watts. GPU performance falls somewhere in between but with significantly higher power consumption.
Memory efficiency represents another crucial advantage. NPUs often feature optimized memory architectures that reduce the bandwidth requirements for AI workloads, allowing larger models to run effectively on systems with limited memory bandwidth.
Use Cases and Applications
The combination of SLMs and NPUs enables a wide range of practical applications that benefit from on-device processing. These use cases span multiple categories, each with specific requirements and benefits.
Productivity applications represent one of the most immediate beneficiaries of on-device AI. Real-time document summarization allows users to quickly extract key points from lengthy documents without sending sensitive information to the cloud. Intelligent writing assistance provides grammar checking, style suggestions, and content enhancement while maintaining privacy. Meeting transcription and analysis can happen in real-time during video calls, providing summaries and action items without external dependencies.
Creative workflows benefit significantly from local AI processing. Image editing tools can leverage AI for background removal, object recognition, and style transfer without uploading personal photos to cloud services. Content generation for text, code, and creative writing can happen instantaneously without internet connectivity. Video processing applications can apply AI-powered effects and enhancements in real-time.
Developer tools represent another exciting category. Code completion and suggestion systems can provide intelligent assistance without sending proprietary code to external services. Local debugging and analysis tools can leverage AI to identify potential issues and suggest improvements. Documentation generation can happen automatically based on code analysis.
Privacy-sensitive applications particularly benefit from on-device processing. Personal financial analysis can leverage AI insights without sharing sensitive financial data. Health and fitness tracking can provide intelligent recommendations while keeping health data completely private. Personal communication tools can offer smart features without compromising message privacy.
Performance Benchmarks and Real-World Testing
Comprehensive testing of SLMs on modern NPU-equipped systems reveals impressive performance characteristics that make on-device AI practical for everyday use. These benchmarks consider multiple factors including raw performance, energy efficiency, and user experience quality.
Language processing benchmarks show that modern SLMs running on NPUs can achieve 85-95% of the quality of their larger cloud-based counterparts for many common tasks. Response times are typically under 100 milliseconds for short queries and scale linearly with output length. Token generation rates of 30-60 tokens per second are common on high-end NPUs.
Image processing tasks demonstrate even more impressive results. Real-time background blur and replacement can operate at 30-60 FPS with minimal CPU usage. Object detection and recognition tasks achieve accuracy rates comparable to cloud services while maintaining sub-50ms latency.
Battery life impact studies show that NPU-accelerated AI tasks consume 5-10x less battery compared to equivalent CPU implementations, making all-day AI-powered productivity feasible on laptop devices.
Challenges and Limitations
Despite the impressive capabilities of on-device AI, several challenges and limitations remain that developers and users must consider when deploying these solutions.
Model size constraints represent the most fundamental limitation. Even with advanced compression techniques, on-device models must remain significantly smaller than their cloud counterparts, which can impact capability for highly complex tasks. Current SLMs excel at many common use cases but may struggle with highly specialized or niche applications that benefit from larger models' broader knowledge base.
Hardware requirements create accessibility barriers. Not all devices include NPUs, and even those that do may not meet the performance thresholds required for smooth AI experiences. The requirement for sufficient RAM and storage for model deployment can be prohibitive on lower-end devices.
Model updating and management present operational challenges. Unlike cloud-based AI where models can be updated centrally, on-device models require local updates that consume bandwidth and storage. Managing multiple specialized models for different tasks can quickly consume device resources.
Privacy and security considerations, while generally improved with on-device processing, introduce new challenges. Protecting locally stored AI models from extraction or tampering requires robust security measures. Ensuring model outputs don't inadvertently expose training data requires careful validation.
The Competitive Landscape
The on-device AI market is rapidly evolving with multiple major players pursuing different strategies and technologies. Understanding the competitive landscape helps predict future developments and identify the most promising platforms.
Microsoft's approach centers around the Copilot+ PC ecosystem, leveraging partnerships with hardware manufacturers to ensure consistent NPU performance across devices. Their strategy emphasizes developer tools and enterprise integration, making it attractive for business deployments.
Apple's approach focuses on tight hardware-software integration across their device ecosystem. The Neural Engine in Apple Silicon provides consistent performance characteristics, while their unified memory architecture offers advantages for AI workloads. However, their closed ecosystem limits third-party innovation compared to more open platforms.
Google's strategy spans multiple fronts, from Pixel devices with specialized AI chips to their broader Android ecosystem. Their expertise in AI research translates to competitive model capabilities, though hardware fragmentation across Android devices creates deployment challenges.
Intel and AMD are positioning themselves as enabling technologies, providing NPU capabilities across a broad range of PC manufacturers. This approach could drive widespread adoption but may result in less optimized experiences compared to more integrated solutions.
Qualcomm's dominance in mobile processors extends to NPU capabilities, making them a key player in laptop and tablet markets as ARM-based processors gain traction in these segments.
Future Outlook and Implications
The trajectory of on-device AI suggests we're at the beginning of a fundamental shift in how AI capabilities are deployed and consumed. Several trends point toward continued growth and sophistication in this space.
Hardware evolution will likely continue the current trajectory of increasing NPU performance while reducing power consumption. Future processor generations may dedicate even larger portions of silicon area to AI acceleration, making powerful on-device AI ubiquitous rather than premium.
Model development will likely focus on increasingly efficient architectures that maintain quality while reducing computational requirements. Techniques like mixture of experts, dynamic neural networks, and specialized task-specific models will enable more sophisticated capabilities within the constraints of edge deployment.
Software ecosystems will mature to provide better development tools, model deployment frameworks, and application integration patterns. This will lower the barrier to entry for developers and enable more widespread adoption of on-device AI features.
Privacy and regulatory trends may accelerate adoption of on-device AI as organizations seek to minimize data exposure and comply with increasingly strict privacy regulations. The ability to provide AI capabilities without data transmission offers compelling compliance advantages.
Development Considerations and Best Practices
For developers looking to leverage on-device AI capabilities, several key considerations and best practices can help ensure successful implementations.
Model selection requires careful analysis of the trade-offs between model size, capability, and target hardware. Developers should benchmark multiple model options on their target devices to identify the optimal balance for their specific use case. Consider using different models for different tasks rather than trying to find one model that handles everything adequately.
Performance optimization involves multiple layers from model quantization and optimization to efficient inference implementation. Leverage hardware-specific optimization libraries and frameworks designed for your target NPU architecture. Profile your application thoroughly to identify bottlenecks and optimization opportunities.
User experience design must account for the characteristics of on-device AI, including variable performance across different devices and the need for graceful degradation when AI features are unavailable. Provide clear feedback about AI processing status and ensure your application remains functional even when AI features are disabled.
Privacy and security implementation should take advantage of on-device processing benefits while implementing appropriate safeguards. Even though data doesn't leave the device, consider encryption for stored models and outputs, especially in enterprise environments.
Conclusion: The Dawn of Ubiquitous AI
The rise of on-device AI powered by Small Language Models and Neural Processing Units represents more than just a technological evolution—it's a fundamental shift toward more private, efficient, and accessible artificial intelligence. The emergence of platforms like Microsoft's Copilot+ PCs demonstrates that the future of AI isn't just about more powerful cloud services, but about bringing AI capabilities directly to users' devices.
As we look toward the future, the implications of this shift extend far beyond improved performance metrics. On-device AI promises to democratize access to AI capabilities, reduce dependence on internet connectivity, enhance privacy protection, and enable new categories of applications that simply weren't possible with cloud-only approaches.
The current generation of SLMs and NPUs represents just the beginning of this transformation. As hardware continues to evolve and models become even more efficient, we can expect on-device AI to become not just competitive with cloud alternatives, but superior for many use cases.
For organizations and developers, the message is clear: the future of AI is hybrid, with on-device capabilities playing an increasingly important role alongside cloud services. Those who begin exploring and implementing on-device AI solutions now will be well-positioned to take advantage of this transformative technology as it continues to mature and expand.
The rise of on-device AI isn't just changing how we build AI applications—it's reshaping our fundamental relationship with artificial intelligence, making it more personal, more private, and more powerful than ever before.