Paper Review — VideoPose3D (CVPR 2019)
3D human pose estimation in video with temporal convolutions and semi-supervised training

In this post, we will understand paper: 3D human pose estimation in video with temporal convolutions and semi-supervised training(CVPR 2019) written by Dario Pavllo et al. and test pre-trained model.
Introduction
- The authors estimate 3D poses in video with a convolutional model based on dilated temporal convolutions over 2D keypoints.
- Main Contribution
- Present a simple and efficient approach for 3D human pose estimation in video based on dilated temporal convolutions on 2D keypoints trajectories.
- Introduce a semi-supervised approach which exploits unlabeled video, and is effective when labeled data is scarce.
- Compared to previous semi-supervised approaches, the suggested method only requires camera intrinsic parameters rather than ground-truth 2D annotations or multi-view imagery with extrinsic camera parameters.
Temporal Dialed Convolutional Model
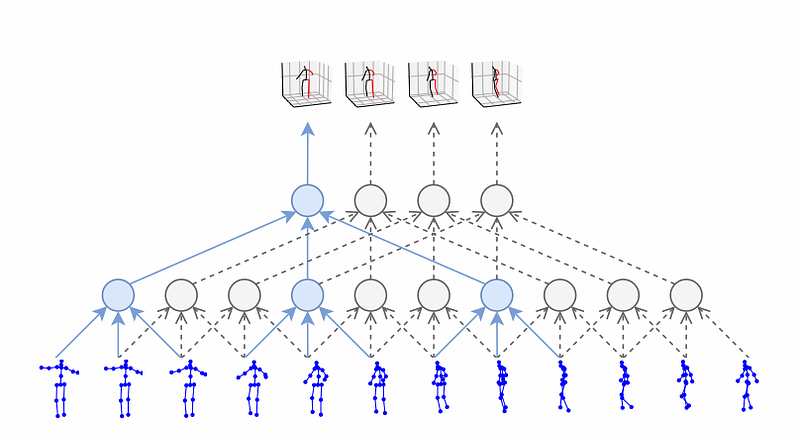
Temporal dialed convolutional model takes 2D keypoint sequences as input and generates 3D pose estimates as output. The bottom blue coordinates are frames from a video. They are needed to encode a sequence of 2D poses from a video and encoded into a sequence of 3D poses. The input and output sequences have the different length.
Model Architecture

- 4 Residual blocks, 0.25 dropout rate, 243 frames, filter size 3, output feature 1024
Input
- 2D keypoints for a receptive field
- 243 frames x 34 channels (17 joints * 2dim(x,y))
Output
- 3D coordinates (1 x 51)
TCN(Temporal Convolutional Network) layer notation(green)
- Example: 2J, 3d1, 1024
- I2J: Input Channel
- 3d1: Conv filter size 3 and Dilation 1
Slice
- The residuals are sliced to match the shape of subsequent tensors.
- Since valid convolution is used, the shape of input tensors for a residual block is different from the shape of output tensors.
- For the first residual block, the residuals are sliced by 3(left and right, symmetrically) to match (241, 1024) with (235, 1024).
Information Flow
Symmetric convolutions
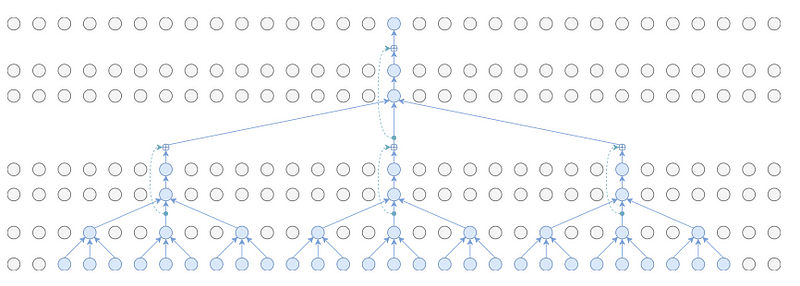
The model is using symmetric convolutions with acausal mode for training, which means each layer now operates over one previous step, the current step, and one future step.
Causal convolutions
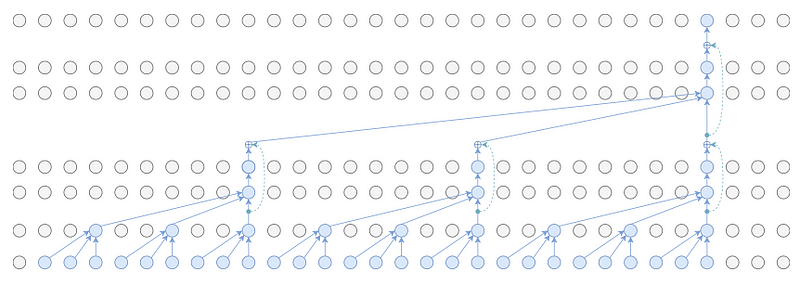
Causal convolutions are used for temporal data which ensures the model cannot violate the ordering. The filter is applied over an area larger than its length by skipping input values with a certain step. A dilated causal convolution effectively allows the network to have very large receptive fields with just a few layers.
Padding
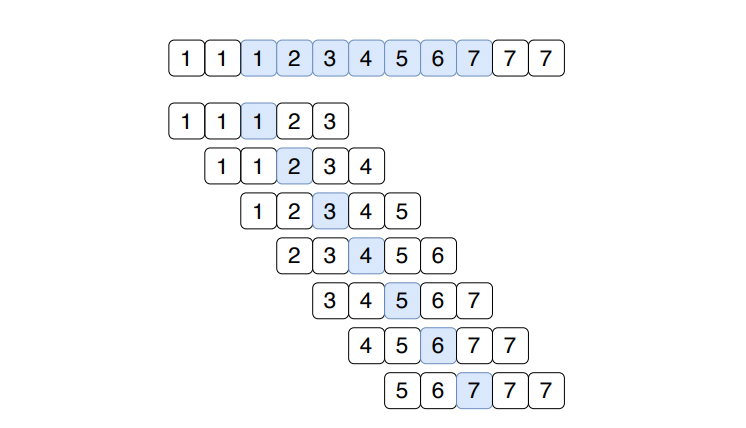
The video is padded by replicating boundary frames. For example, when a video has 7 frames, it is used to train a model with a receptive field of 5 frames. The authors generate a training example for each of the 7 frames, such that only the center frame is predicted.
Semi-supervised approach
Semi-supervised Training
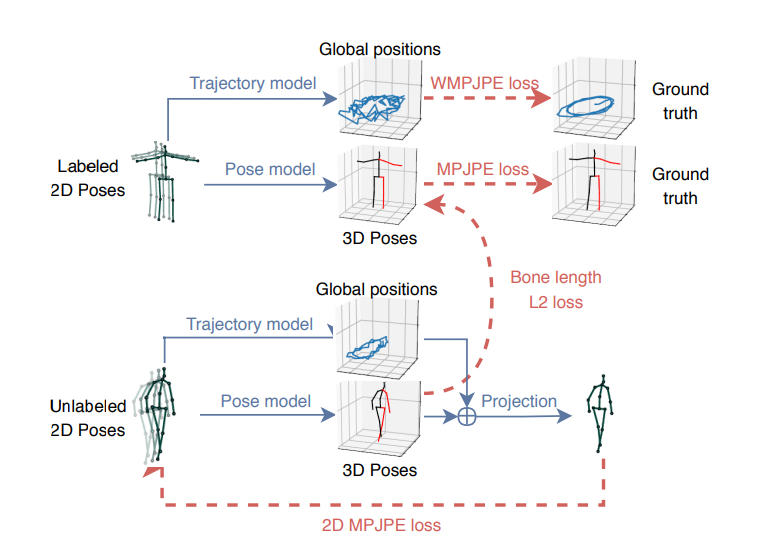
A supervised loss is trained for labeled data and autoencoder loss is implemented when using unlabeled data. The two objectives are optimized jointly. The labeled data occupies the first half of a batch, and the unlabeled data occupies the second half.
For supervised loss, the ground truth 3D poses is used as targets. The unsupervised component acts as a regularizer. The autoencoder predicts 3D poses which are projected back to 2D. For the labeled data we use the ground truth 3D poses as target and train a supervised loss. The unlabeled data is used to implement an autoencoder loss where the predicted 3D poses are projected back to 2D and then checked for consistency with the input. Reconstruction error(MPJPE) is used to check for consistency with the input. Bone length L2 Loss is added for a soft constraint to approximately match the mean bone lengths of the subjects in the unlabeled batch to the subjects of the labeled batch.
Trajectory Model
A trajectory model is a network to create 3D trajectory with 2D poses while mapping 2D poses to 3D. The method is used to regress the 3D trajectory of a person, so that the back-projection to 2D can be performed correctly.
Loss Function
- Supervised Loss: MPJPE(mean per-joint position error) is used to calculate the mean Euclidean distance between predicted joint positions and 3D ground-truth joint positions.
- Global Trajectory Loss: For the trajectory, a weighted mean per-joint position error (WMPJPE) loss function is optimized.
- y_z means the inverse of the ground-truth depth in camera space. The authors weight each sample using it.
Experiments
Dataset: Human3.6M
- 3.6 million images
- 11 subjects (7 subjects annotated)
- 15 activities such as walking, eating, sitting, making a phone call and engaging in a discussion
- 2d joint locations and 3d ground truth positions are available
Dataset: HumanEva
- A smaller dataset that has been largely used to benchmark.
- 3 subjects, 3 actions(Walk, Jog, Box)
- 15 joint skeletons
2D pose estimation
- Backbone Model: Mask R-CNN with ResNet-101-FPN, Cascaded Pyramid Network with ResNet-50
- Process: Pre-trained on MS COCO and fine-tuned on Human3.6
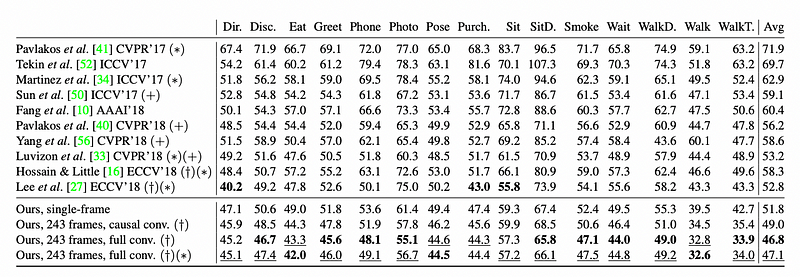
MPJPE
P-MPJPE
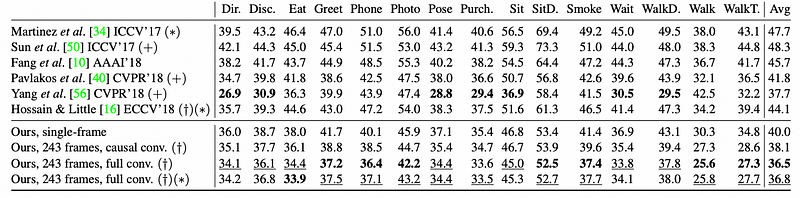
P-MPJPE means reconstruction errors after rigid alignment with the ground truth. The model has lower average error than all other approaches under both protocols.
Qualitative Results
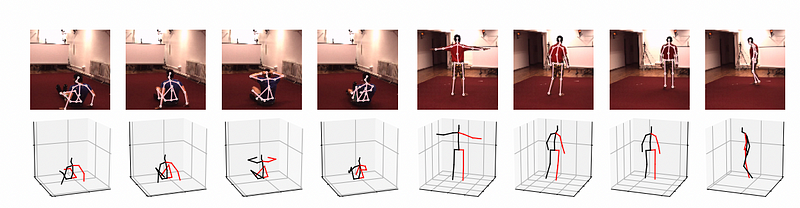
The figure above shows qualitative results for two videos, illustrating video frames with 2D pose overlay and 3D reconstruction.
Test a Pre-trained Model
Let’s test the pre-trained model for Human3.6M dataset . Firstly, you can download the processed data from here which I found MHFormer repository in data/ directory.
To download the pre-trained model on Human3.6M, run:
mkdir checkpoint
cd checkpoint
wget <https://dl.fbaipublicfiles.com/video-pose-3d/pretrained_h36m_cpn.bin>
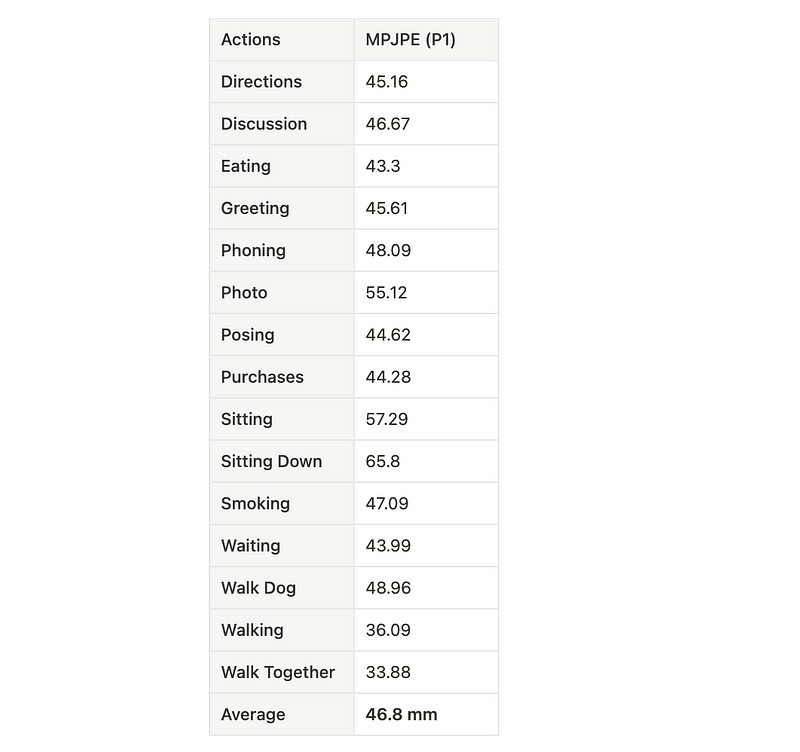
cd ..The pre-trained model has 46.8 mm of MPJPE (P1). This uses fine-tuned CPN detections, bounding boxes from Mask R-CNN, and an architecture with a receptive field of 243 frames.
To test on Human3.6M, run:
python run.py -k cpn_ft_h36m_dbb -arc 3,3,3,3,3 -c checkpoint --evaluate pretrained_h36m_cpn.binIt takes 3~5 minutes to run the code using PyCharm.
The MPJPE is same as reported results under Protocol 1:

Thank you for reading :)