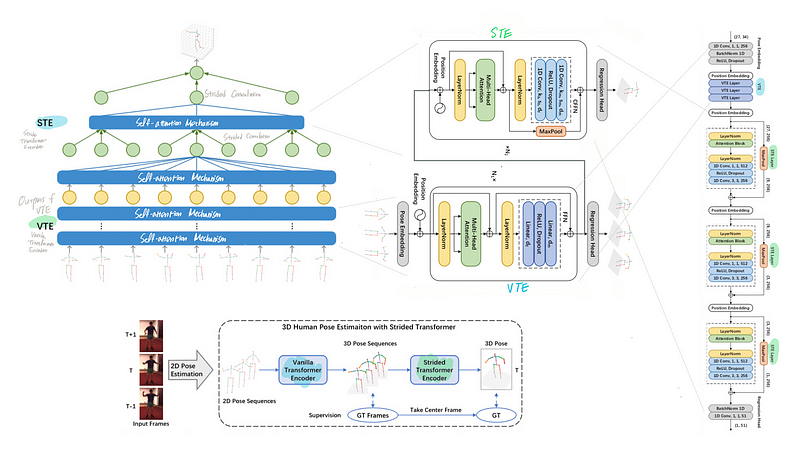
Paper Review — Strided Transformer (TMM 2022)
Strided Transformer is a monocular 3D pose estimation model which lifts a long sequence of 2D joint locations to a single 3D pose.


- Strided Transformer is a monocular 3D pose estimation model which simply and effectively lifts a long sequence of 2D joint locations to a single 3D pose.
- Vanilla Transformer Encoder (VTE) is used to model long-range dependencies of 2D pose sequences.
- Strided Transformer Encoder (STE) is a modified VTE and STE layers contains strided convolutions to progressively shrink the sequence length and aggregate information from local contexts, which reduces the redundancy of the sequence.
class Model(nn.Module):
def __init__(self, args):
super().__init__()self.encoder = nn.Sequential(
nn.Conv1d(2*args.n_joints, args.channel, kernel_size=1),
nn.BatchNorm1d(args.channel, momentum=0.1),
nn.ReLU(inplace=True),
nn.Dropout(0.25)
)self.Transformer = [Transformer](<https://www.notion.so/381239ee9a904448a68954fe1752c9b2>)(args.layers, args.channel, args.d_hid, length=args.frames)
self.Transformer_reduce = Transformer_reduce(len(args.stride_num), args.channel, args.d_hid, \\
length=args.frames, stride_num=args.stride_num)
self.fcn = nn.Sequential(
nn.BatchNorm1d(args.channel, momentum=0.1),
nn.Conv1d(args.channel, 3*args.out_joints, kernel_size=1)
)self.fcn_1 = nn.Sequential(
nn.BatchNorm1d(args.channel, momentum=0.1),
nn.Conv1d(args.channel, 3*args.out_joints, kernel_size=1)
)def forward(self, x):
B, F, J, C = x.shape
x = rearrange(x, 'b f j c -> b (j c) f').contiguous()
x = self.encoder(x)
x = x.permute(0, 2, 1).contiguous()
x = self.Transformer(x)
x_VTE = x
x_VTE = x_VTE.permute(0, 2, 1).contiguous()
x_VTE = self.fcn_1(x_VTE)
x_VTE = rearrange(x_VTE, 'b (j c) f -> b f j c', j=J).contiguous()
x = self.Transformer_reduce(x)
x = x.permute(0, 2, 1).contiguous()
x = self.fcn(x)
x = rearrange(x, 'b (j c) f -> b f j c', j=J).contiguous()
return x, x_VTEStrided Transformer network

Strided Transformer network contains a Vanilla Transformer Encoder (VTE) followed by a Strided Transformer Encoder (STE).
Vanilla Transformer Encoder
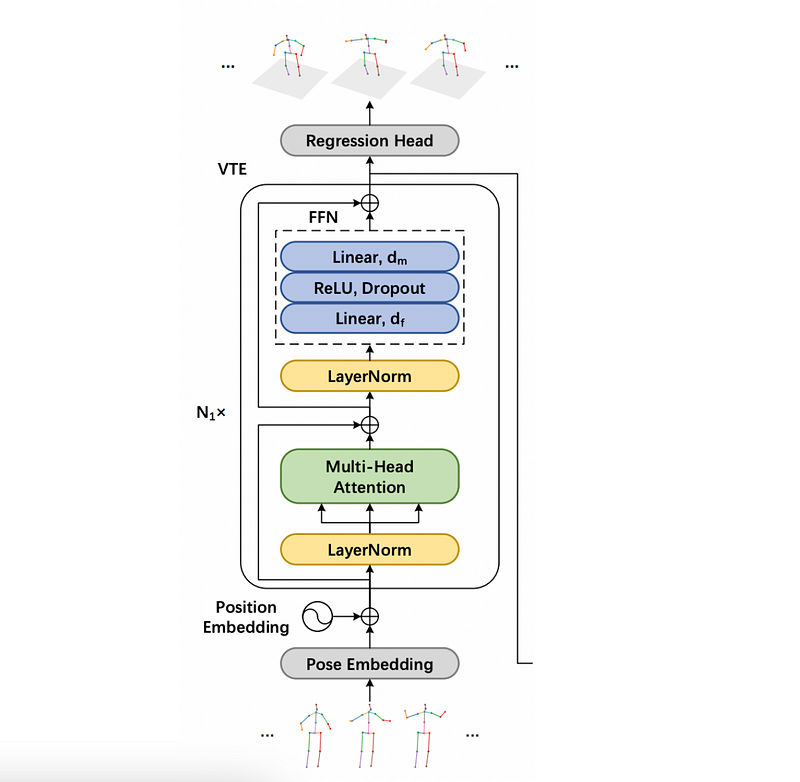
VTE is first used to model long-range information and is supervised by the full sequence scale to enforce temporal smoothness.
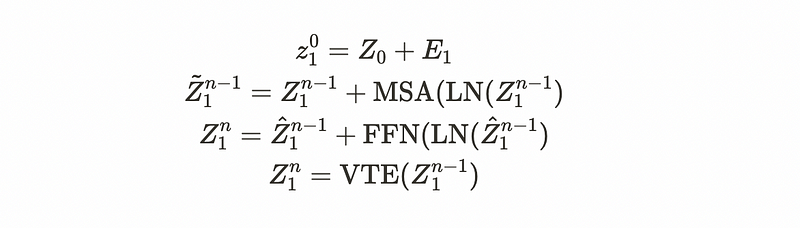
class Transformer(nn.Module):
def __init__(self, n_layers=3, d_model=256, d_ff=512, h=8, dropout=0.1, length=27):
super(Transformer, self).__init__()self.pos_embedding = nn.Parameter(torch.randn(1, length, d_model))
self.model = self.make_model(N=n_layers, d_model=d_model, d_ff=d_ff, h=h, dropout=dropout)
def forward(self, x, mask=None):
x += self.pos_embeddingx = self.model(x, mask)return xdef make_model(self, N=3, d_model=256, d_ff=512, h=8, dropout=0.1):
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
model = Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N)
return modelStrided Transformer Encoder
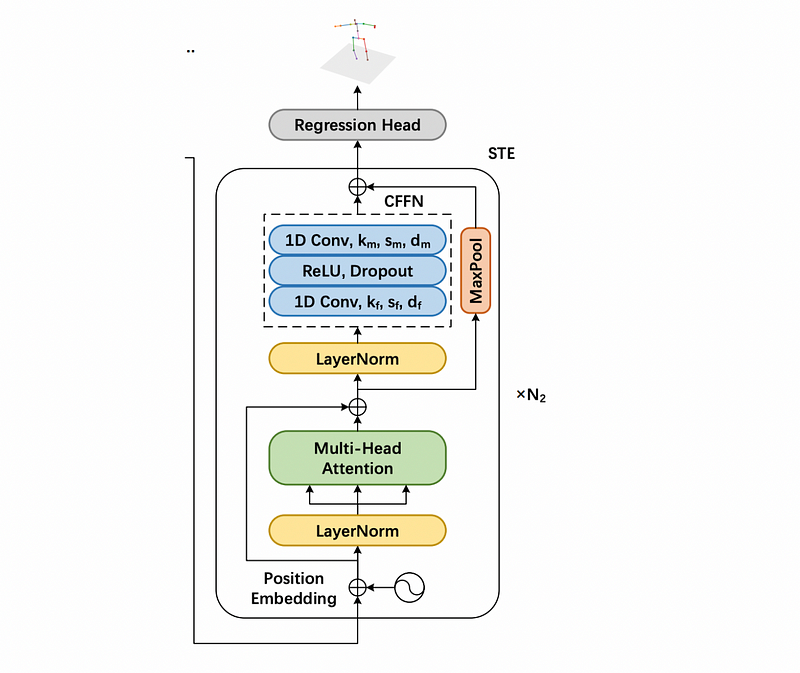
STE is built upon Z, the outputs of VTE. The learnable position embeddings E with strided factor S are used because of the different sequence lengths.
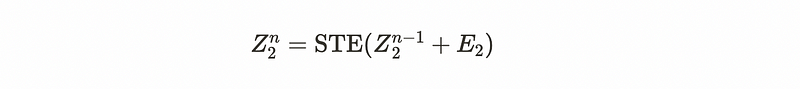
class Transformer(nn.Module):
def __init__(self, n_layers=3, d_model=256, d_ff=512, h=8, length=27, stride_num=None, dropout=0.1):
super(Transformer, self).__init__()self.length = lengthself.stride_num = stride_num
self.model = self.make_model(N=n_layers, d_model=d_model, d_ff=d_ff, h=h, dropout=dropout, length = self.length)def forward(self, x, mask=None):
x = self.model(x, mask)return xdef make_model(self, N=3, d_model=256, d_ff=512, h=8, dropout=0.1, length=27):
# n : encoder layer
# d_ff : hidden units for both VTE and STE
# h : attention headc = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)model_EncoderLayer = []
for i in range(N):
ff = PositionwiseFeedForward(d_model, d_ff, dropout, i, self.stride_num)
model_EncoderLayer.append(EncoderLayer(d_model, c(attn), c(ff), dropout, self.stride_num, i))model_EncoderLayer = nn.ModuleList(model_EncoderLayer)model = Encoder(model_EncoderLayer, N, length, d_model)
return modelMulti-head self-attention
Each STE layer consists of a multi-head self-attention (MSA) and a convolutional feed-forward network(CFFN).
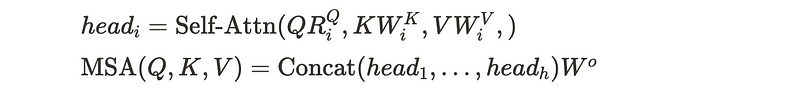
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
if mask is not None:
mask = mask.unsqueeze(1)
nbatches = query.size(0)
query, key, value = [l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)Convolutional feed-forward network
Fully-connected layers in FFN of VTE are replaced with strided convolutions.
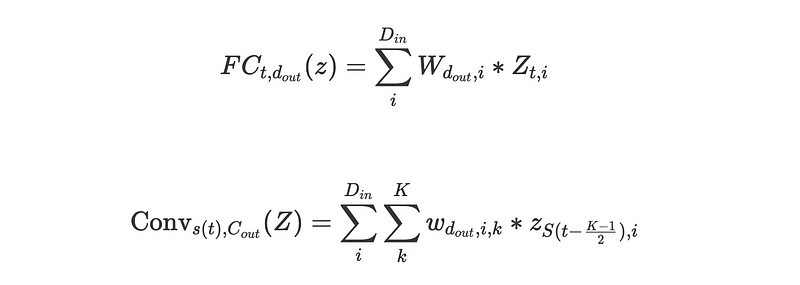
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1, number = -1, stride_num=-1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Conv1d(d_model, d_ff, kernel_size=1, stride=1)
self.w_2 = nn.Conv1d(d_ff, d_model, kernel_size=3, stride=stride_num[number], padding = 1)
self.gelu = nn.ReLU()
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = x.permute(0, 2, 1)
x = self.w_2(self.dropout(self.gelu(self.w_1(x))))
x = x.permute(0, 2, 1)
return x
Full-to-Single Prediction
A full-to-single scheme refines the intermediate predictions to produce more accurate estimations rather than using a single component with a single output. The model is supervised at both full sequence scale and single target frame scale.
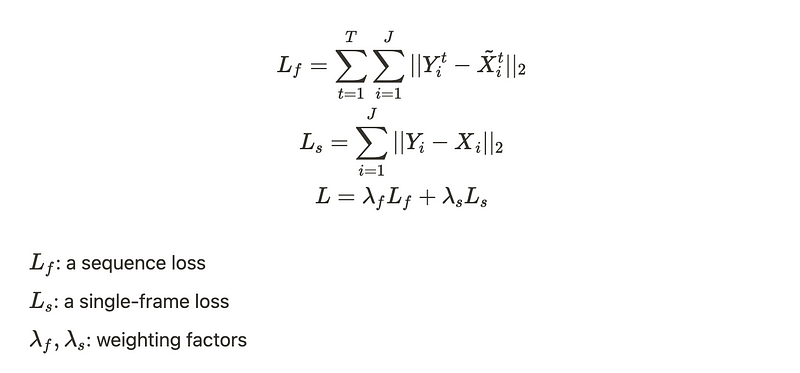
The below is a part of step module for training.
if opt.refine:
loss = mpjpe_cal(output_3D, out_target_single)
else:
loss = mpjpe_cal(output_3D_VTE, out_target) + mpjpe_cal(output_3D, out_target_single)
N = input_2D.size(0)
loss_all['loss'].update(loss.detach().cpu().numpy() * N, N)Experiments
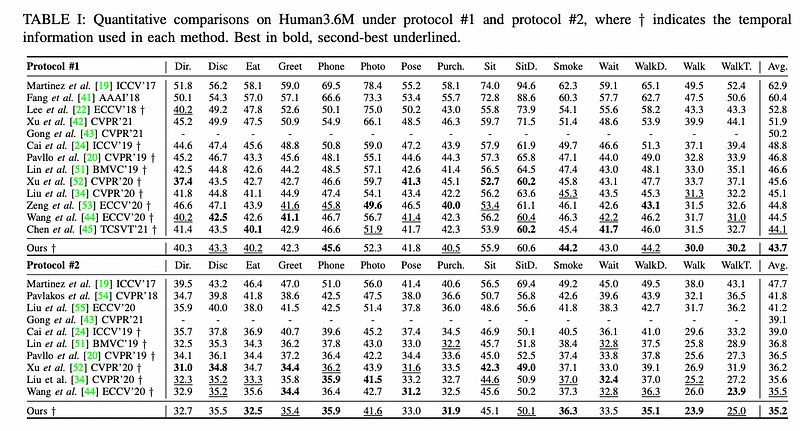
The Strided Transformer achieves state-of-the-art results with fewer parameters on Human3.6M.
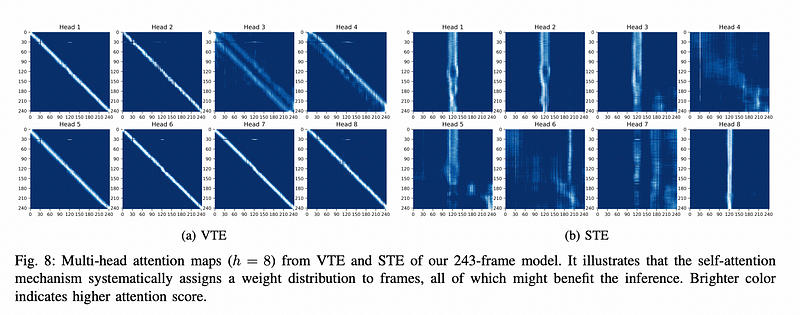
- VTE identifies only important sequences that are close to the input frames and enforces temporal consistency across frames.
- STE learns a specific representation from the input sequences using both past and future data. STE improves the representation ability to reach an optimal inference.
Thank you for reading!