Paper Review — MHFormer
Introduction

Paper Review — MHFormer (CVPR 2022)
Introduction
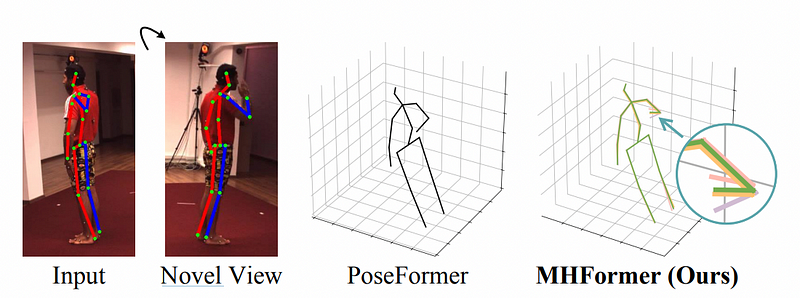
MHFormer: Multi-Hypothesis Transformer for 3D Human Pose Estimation(CVPR 2022) is a model Estimating 3D human poses from monocular videos. Multi-Hypothesis Transformer learns spatio-temporal representations of multiple plausible hypotheses and build strong relationships across them. A recent state-of-the-art 3D HPE method creates a single estimation, whereas MHFormer generates multiple hypotheses and synthesizes a 3D pose.
Overview of Concepts
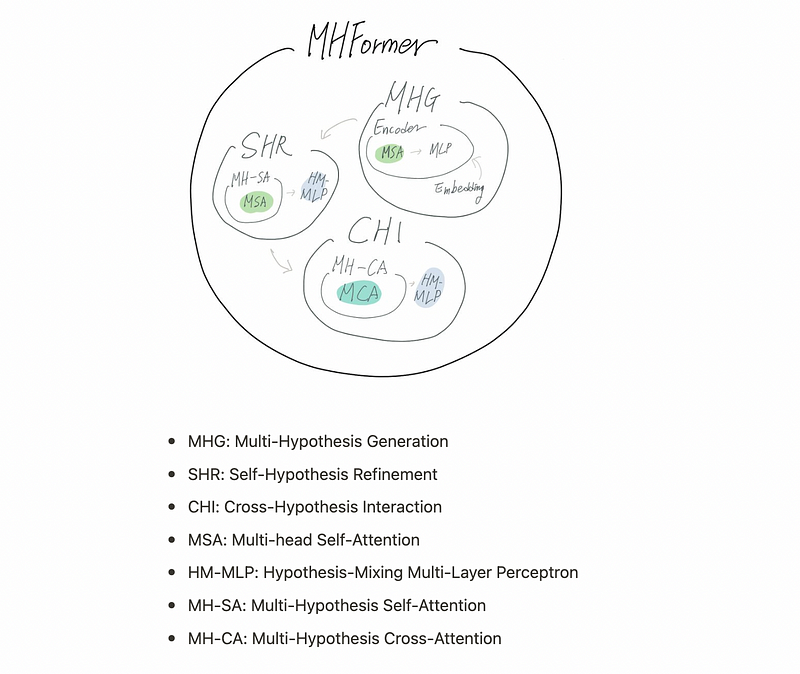
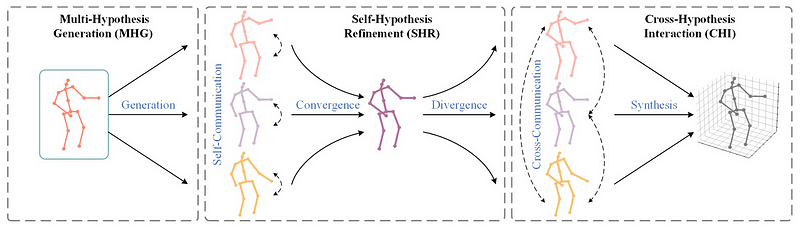
- MHG: Multi-Hypothesis Generation
- SHR: Self-Hypothesis Refinement
- CHI: Cross-Hypothesis Interaction
- MSA: Multi-head Self-Attention
- HM-MLP: Hypothesis-Mixing Multi-Layer Perceptron
- MH-SA: Multi-Hypothesis Self-Attention
- MH-CA: Multi-Hypothesis Cross-Attention
Three Stages of MHFormer
- MHG: module generates multiple initial representations and several multi-level features in the spatial domain.
- SHR: module refines every single-hypothesis feature, which consists of two new blocks: multi-hypothesis self-attention (MH-SA) and hypothesis-mixing multi-layer perceptron (MLP).
- CHI: module models interactions among multi-hypothesis features with the help of multi-hypothesis cross-attention (MH-CA) composed of multi-head cross-attention (MCA) elements in parallel.
Multi-Hypothesis Transformer (MHFormer)
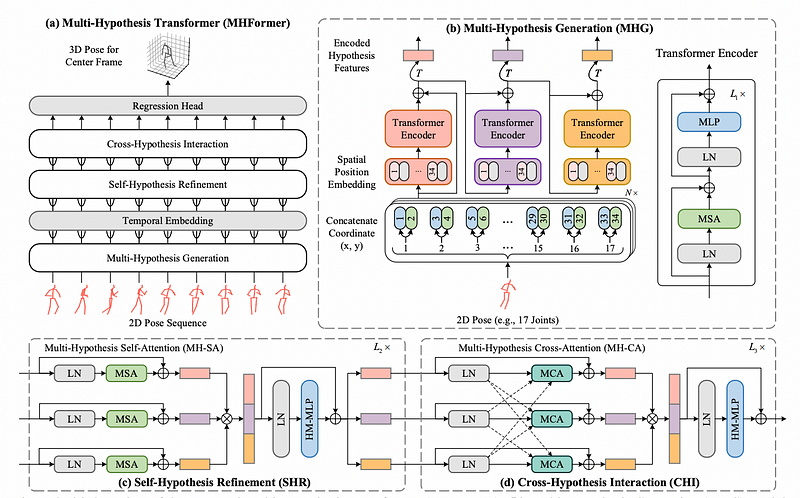
From (a) overview of Multi-Hypothesis Transformer (MHFormer), (b) Multi-Hypothesis Generation (MHG) module extracts the intrinsic structure information of human joints within each frame and generates multiple hypothesis representations. N is the number of input frames and T is the matrix transposition. © Self-Hypothesis Refinement (SHR) module is used to refine single-hypothesis features. (d) Cross-Hypothesis Interaction (CHI) module enables interactions among multi-hypothesis features.
Multi-Hypothesis Generation (MHG)
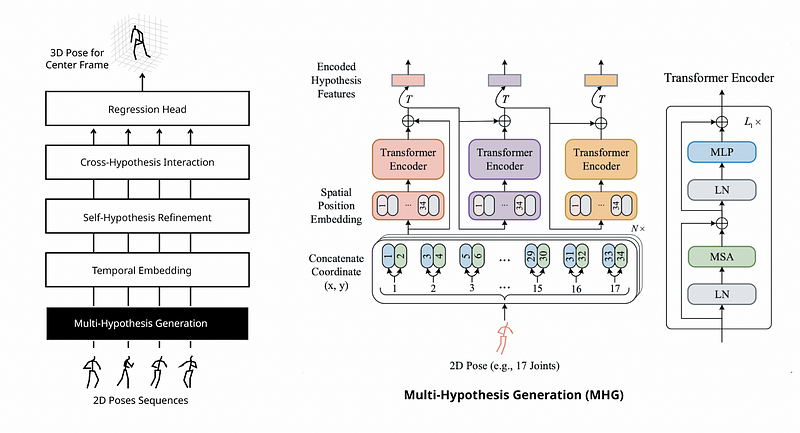
MHG is introduced to model the human joint relations and initialize the multi-hypothesis representations. MHG concatenates the (x, y) coordinates of joints and retains their spatial information of joints via a spatial position embedding.
A skip residual connection is applied between the original input and output features from the encoder in order to encourage gradient propagation. The outputs of the MHG can be initial representations of different pose hypotheses.

Temporal Embedding
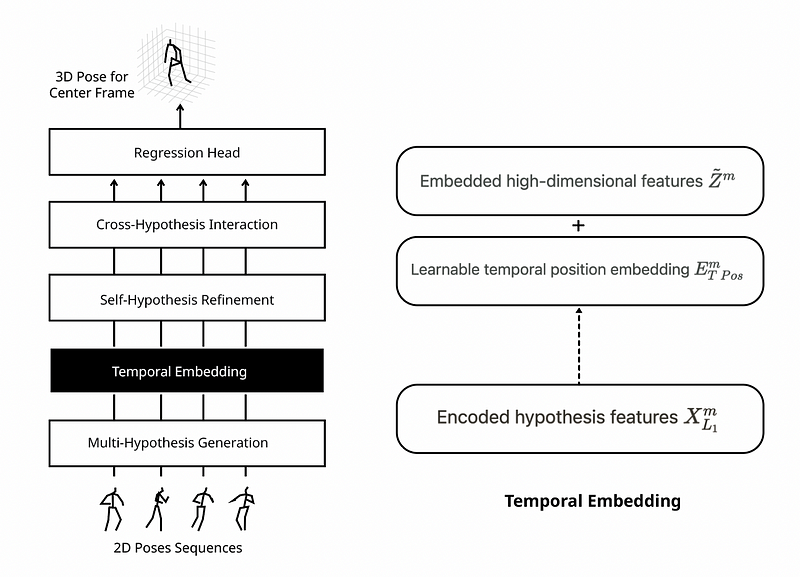
The spatial domain is converted into the temporal domain in order to exploit temporal information. Encoded hypothesis features X are embedded high-dimensional features Z utilizing learnable temporal position embedding E to retain positional information of frames.
Self-Hypothesis Refinement (SHR)
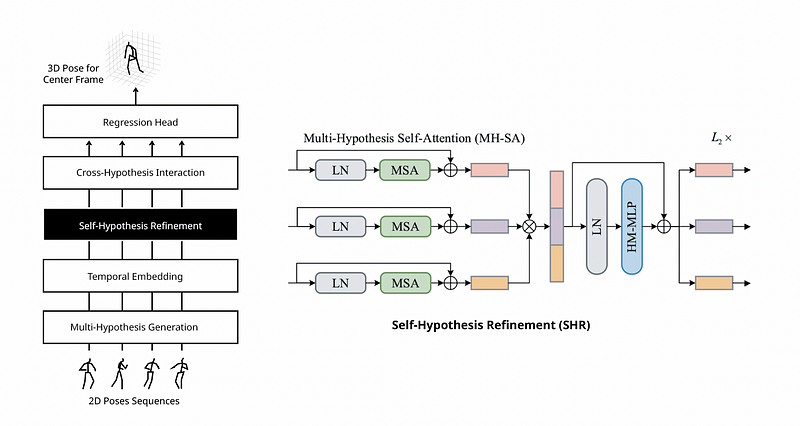
Each SHR layer consists of a multi-hypothesis self-attention (MH-SA) block and a hypothesis-mixing MLP block.
Multi-hypothesis Self-attention (MH-SA) aims to capture single-hypothesis dependencies within each hypothesis independently for self-hypothesis communication.

Multi-head self-attention (MSA) helps Elements interact with each other.
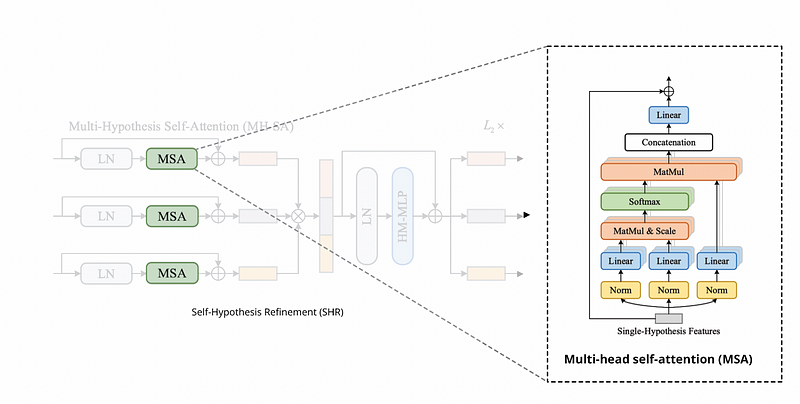
Hypothesis-Mixing MLP (HM-MLP) is added to exchange information across hypotheses MH-SA.
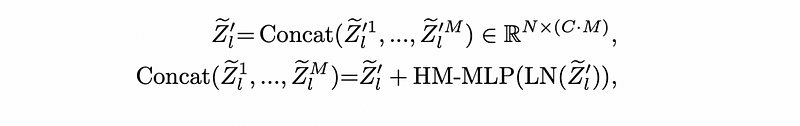
Cross-Hypothesis Interaction (CHI)
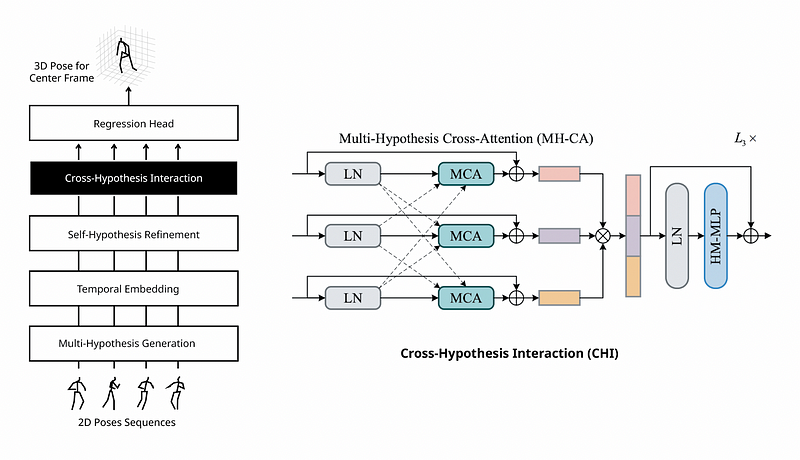
Cross-Hypothesis Interaction (CHI) help the multi-hypothesis features interact each other with two blocks: multi-hypothesis cross-attention (MH-CA) and hypothesis-mixing MLP (HM-MLP).
Multi-Hypothesis Cross Attention (MH-CA) captures mutual multi-hypothesis correlations for cross-hypothesis communication. MH-CA is composed of multiple multi-head cross-attention (MCA) elements in parallel.
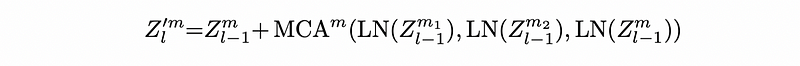
The multiple hypotheses(z) are regarded as queries, keys. For example, Z(Layer 3) can be MCA(Q, K, V) + Z(Layer 2).
Multi-head Cross-Attention (MCA) measures the correlation among cross-hypothesis features. MH-CA requires only 3 MCA blocks.
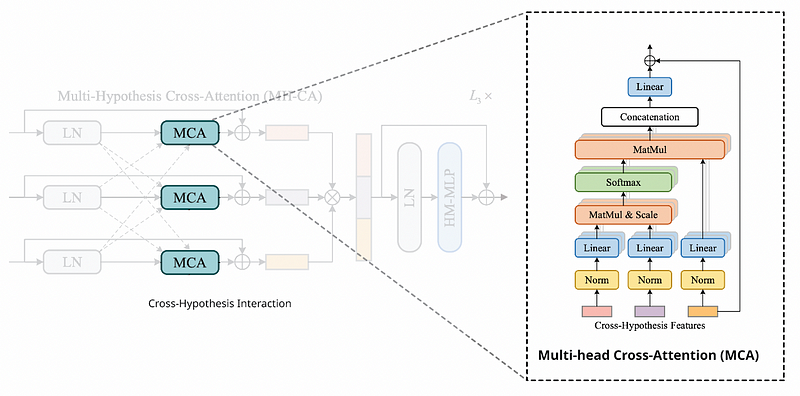
Hypothesis-Mixing MLP (HM-MLP) in CHI operates same as HM-MLP in SHR.
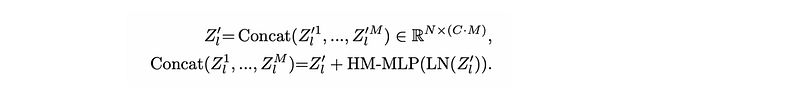
Regression Head
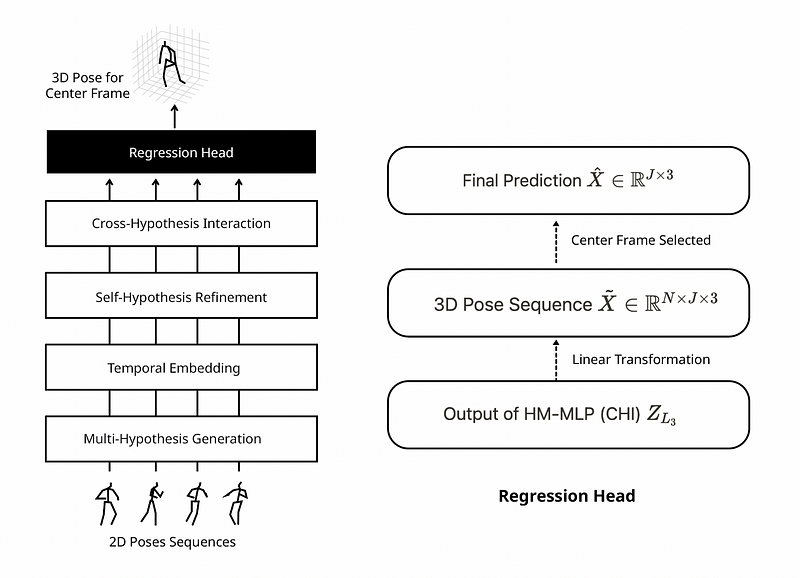
A linear transformation layer is applied on the output Z to perform regression to produce the 3D pose sequence. The 3D pose of the center frame is selected from X as the final prediction.
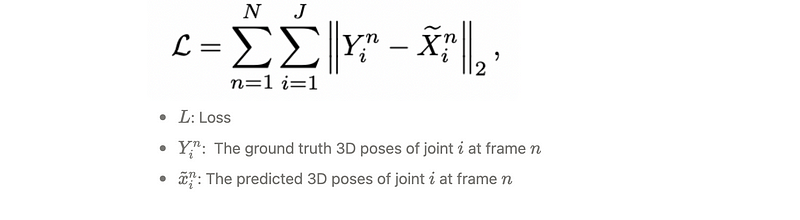
Loss
The model is trained with a Mean Squared Error (MSE) loss.
Experiments
Quantitative Results
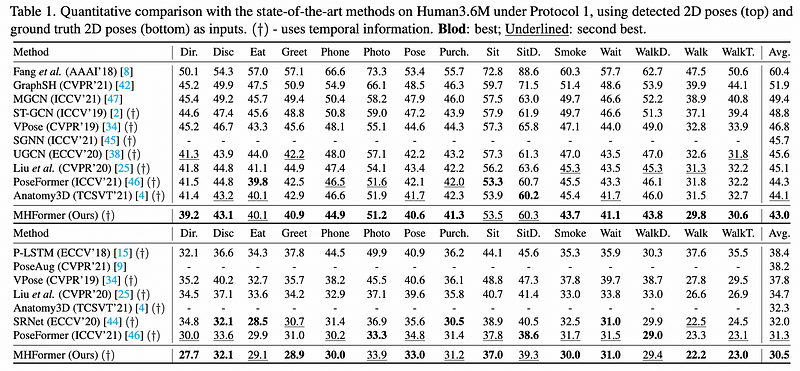
MHFormer outperforms all previous state-of-the-art methods by a large margin under both Protocol 1 (43.0 mm) using 2D detected poses and ground truth 2D poses.
Qualitative Results & Ablation Study
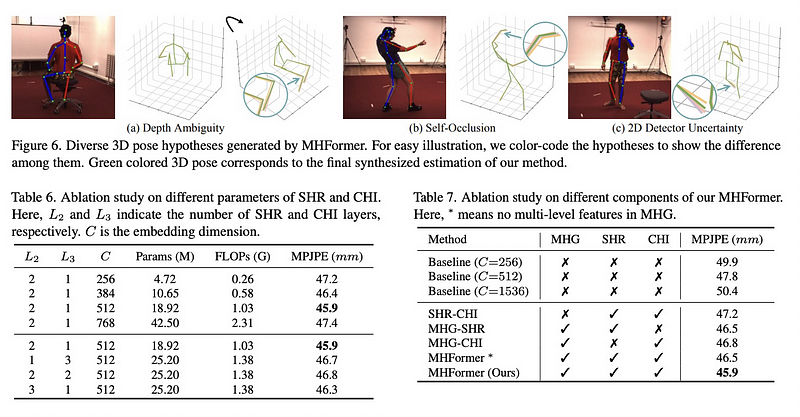
Figure 6. shows diverse 3D pose hypotheses using color-coding. Green colored 3D pose corresponds to the final synthesized estimation of our method.
Table 6. shows the effect of different parameters of SHR and CHI. L2 and L3 indicate the number of SHR and CHI layers and C is the embedding dimension. The performance is improved when the embedding dimension is enlarged from 256 to 512.
Figure 7 shows the effect of model components. The baseline model is prone to overfitting due to the large number of parameters. MHFormer built upon MHG, SHR, and CHI outperforms baseline models.
Conclusion
MHFormer is a three-stage framework for monocular task. Transformer-based method is proposed to solve the ambiguous inverse problem. Simpler computational complexity can be expected in the near future.