Paper Review: Making LLMs Better Many-to-Many Speech-to-Text Translators with Curriculum Learning

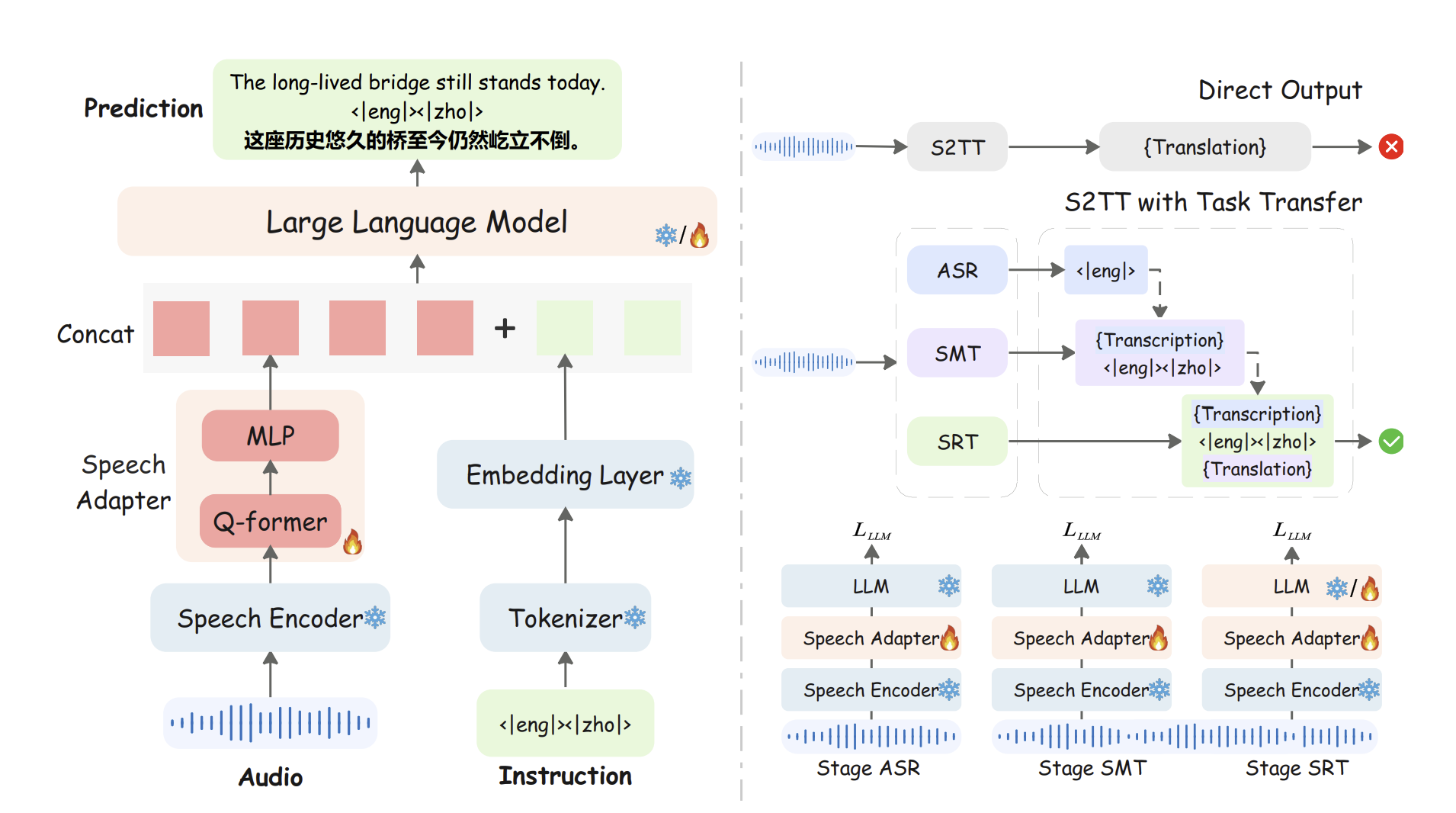
In this post, I’m reviewing Making LLMs Better Many-to-Many Speech-to-Text Translators with Curriculum Learning (ACL 2025 ) without exotic training tricks. The recipe—called LLM-SRT—keeps a frozen Whisper encoder, adds a lightweight speech adapter (Q-Former + MLP), and fine-tunes in three stages: (1) ASR, (2) speech-aided MT (SMT/MMT), and (3) SRT, where the model generates both a transcript and a translation from speech. On FLEURS, it reaches state-of-the-art average performance across 15×14 directions under <10 hours of speech per language, and it scales cleanly to CoVoST-2.
Methodology
The method explicitly defines three supervised tasks the model cycles through during training:
- ASR: input audio + language tag → output transcription.
- SMT (speech-aided MT): input audio + its transcript + language-pair tag → output translation.
- SRT: input audio + language-pair tag → output both {transcription} and {translation} in one pass. The paper uses minimalist instruction tokens (e.g.,
<|eng|><|deu|>) that also serve as output separators during SRT generation.
Architecture. LLM-SRT = frozen Whisper encoder → Q-Former-based speech adapter (with an MLP projector) → LLM. The adapter compresses long speech features into nq fixed queries (set to 80), then projects them to the LLM’s hidden size and concatenates with text embeddings before decoding. This maintains low sequence length at the LLM and speeds up inference.
Curriculum learning.
- ASR stage builds robust speech–text alignment and broad language coverage while training only the adapter.
- SMT stage “activates” the LLM’s MT capability by feeding both audio and transcripts.
- SRT stage switches to audio-only generation of transcript + translation; here the LLM may be optionally unfrozen (while still training the adapter) for extra gains.

What the authors actually built
At a high level, the system is: Whisper (frozen) → Q-Former adapter (learned) → LLM. The adapter compresses long audio features into a fixed set of queries (the paper uses 80) so the LLM sees a short, stable sequence. This keeps compute low and enables fast inference while the LLM handles the language work.
Why the 3-stage curriculum matters
Jumping directly from speech to translation is hard, especially in low-resource regimes. The authors instead activate the LLM’s MT prior step-by-step:
- Stage 1 — ASR: learn robust speech–text alignment.
- Stage 2 — SMT/MMT: feed audio + transcript and train the LLM to translate; this explicitly bridges MT ↔ S2TT.
- Stage 3 — SRT: feed audio only and generate transcription + translation in one pass.
Minimal instruction tokens (e.g., <|eng|><|deu|>) double as output separators so the model naturally emits “{transcript} <|eng|><|deu|> {translation}.”
Experimental setup
- Model sizes: 3B / 7B / 32B variants. Training primarily updates the adapter; in SRT, the LLM can be unfrozen (e.g., LoRA) for extra performance.
- Datasets:
- ASR: Common Voice for robust alignment.
- SMT & SRT: FLEURS (many-to-many, ~10–12 h per language) and CoVoST-2 (broader coverage).
- Optimization & hardware: AdamW, LR 1e-4, 1,000 warmup steps. Reported training on 4×A100 GPUs; 3B/7B trained ~3 days, 32B ~7 days (authors’ environment).
- Instruction design: short language tags (e.g.,
<|eng|>,<|zho|>,<|eng|><|deu|>) are used both to specify tasks and to segment SRT outputs.
Results
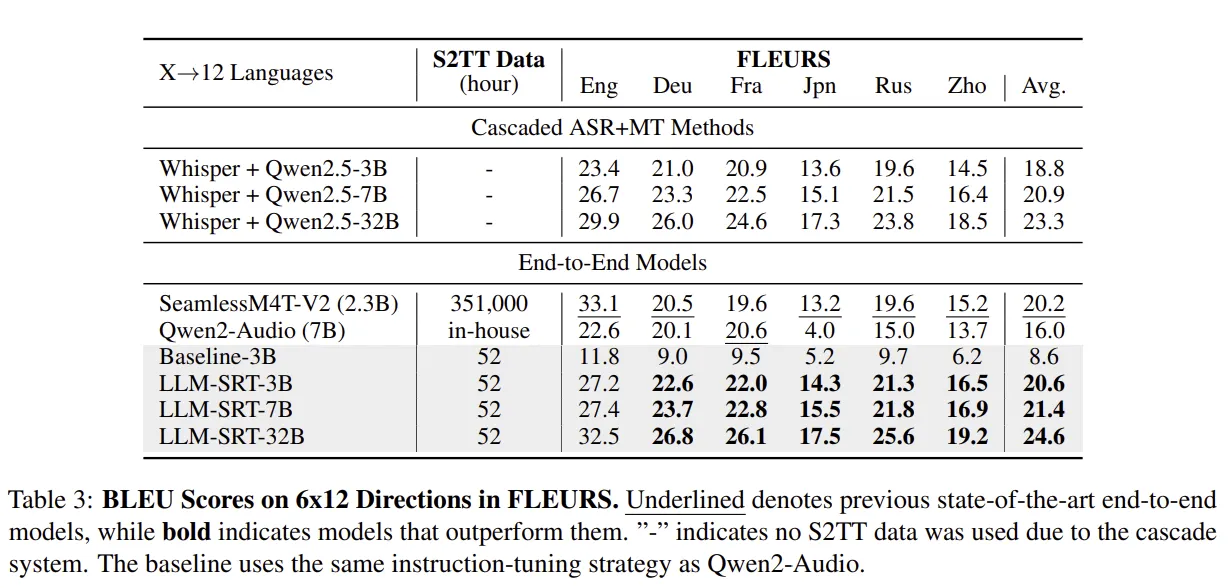
- Many-to-many SOTA on FLEURS: The model achieves state-of-the-art average performance across 15×14 directions in low-resource settings, while also showing robustness on CoVoST-2.
- Ablations support the curriculum: Removing ASR pretraining drops BLEU by ~2.3; skipping SMT or SRT causes additional declines (−1.1 and −4.9 BLEU respectively), confirming each stage’s contribution.
- Inference speed: With 80-query compression, LLM-SRT-7B shows about 3× faster throughput than a similar-size Qwen2-Audio baseline on 1,000 samples using 4×4090 FP16 inference.
Datasets, scale, and results (recap)
The paper trains 3B/7B/32B variants and evaluates across FLEURS (many-to-many) and CoVoST-2. The main headline: best average performance over 210 directions (15 languages) on FLEURS with under 10–12 hours per language; plus speed wins vs. a similar-size Qwen2-Audio baseline thanks to the 80-query adapter.
Code snippets
1) Install + models (LLM-SRT)
The official README keeps it simple—conda env, editable install, and three model pulls (encoder/adapter/LLM):
# environment
conda create -n llm-srt python=3.10
conda activate llm-srt
git clone <https://github.com/yxduir/LLM-SRT> && cd LLM-SRT
pip install -e .
sudo apt install ffmpeg
pip install -r requirements.txt
# models
cd models/
git lfs clone <https://huggingface.co/yxdu/llm-srt>
git lfs clone <https://huggingface.co/openai/whisper-large-v3>
git lfs clone <https://huggingface.co/Qwen/Qwen2.5-3B> # 3B option
LLM-SRT (Github)
2) Data layout for many-to-many (LLM-SRT)
Training examples are JSONL. The prompt encodes the language pair; the gt concatenates transcript + prompt + translation:
{"audio": "eng/test/139.wav",
"source": "fleurs_eng_zho",
"prompt": "<|eng|><|zho|>",
"gt": "They have feet with scales and claws, they lay eggs, and they walk on their two back legs like a T-Rex.<|eng|><|zho|>它们脚上有鳞片和爪子,会产卵,还像霸王龙一样用两条后腿走路。"}
3) One-liners to train & infer (LLM-SRT)
Stage selection is handled via a mode flag inside the script:
# train (set mode=asr|smt|srt in the script)
bash examples/st_covost2/scripts/all.sh
# inference (local or HF checkpoints)
bash examples/st_covost2/scripts/infer_all.sh
bash examples/st_covost2/scripts/infer_hf.sh
LLM-SRT (Github)
4) Prefer a toolkit?
The same recipe also lives in SLAM-LLM under the examples/recipes list as “CoT-ST”, handy for scaling or swapping encoders/LLMs.
Closing take
This work is refreshingly engineering-friendly: a frozen encoder, a compact adapter, and a small LLM—guided by a curriculum that activates the right capabilities at the right time. The result is strong many-to-many S2TT under tight data budgets, plus fast inference from the 80-query bottleneck. If you already have MT-ready LLMs, this is one of the leanest paths to speech translation at scale.