Optimizing Azure OpenAI Service: Base Model Deployment, Fine-Tuning, and Decoding Parameters
Azure OpenAI Service offers powerful tools to deploy, fine-tune, and interact with GPT models, making it essential to understand the…

Azure OpenAI Service offers powerful tools to deploy, fine-tune, and interact with GPT models, making it essential to understand the various parameter settings to achieve optimal performance. In this guide, we will explore the key configurations for deploying base models, fine-tuning them, and using the Chat Playground efficiently. The knowledge of these tools will enable users to maximize their output quality, ensure scalability, and customize GPT models effectively to suit varied use cases.
1. Base Model Deployment Settings
Deploying a GPT model on Azure involves setting up token limits and request parameters. Below are the key configurations visible in the deployment interface, which govern how much data the model can handle and the frequency of requests it can process.
Understanding Tokens
A token is the smallest unit of text that a language model like GPT processes. Tokens can represent:
- Words: Simple words like “cat” or “dog” are typically one token each.
- Word Parts: Longer or more complex words may be split into multiple tokens. For example, “artificial” might be split into “arti” and “ficial.”
- Punctuation: Characters like
,,.or?are considered separate tokens. - Whitespace: Spaces between words are also tokenized.
Tokens vs. Characters
Tokens differ from characters in how text is processed. For instance: “Hello, world!” contains 13 characters but is typically processed as 3 tokens:
- “Hello”
- “,”
- “world!”
The difference arises because tokens are optimized for efficient language processing, considering both syntax and semantics.
Practical Significance of Tokens
- Token Limits: GPT models have a maximum number of tokens they can handle in a single request, including both input and output tokens. For example: GPT-4 supports requests up to 8,000 or 32,000 tokens, depending on the model configuration.
- Cost Management: API usage is billed based on the number of tokens processed.
- Efficiency: Understanding tokenization allows users to optimize input prompts and model outputs effectively.
Token Limits for Model Deployment
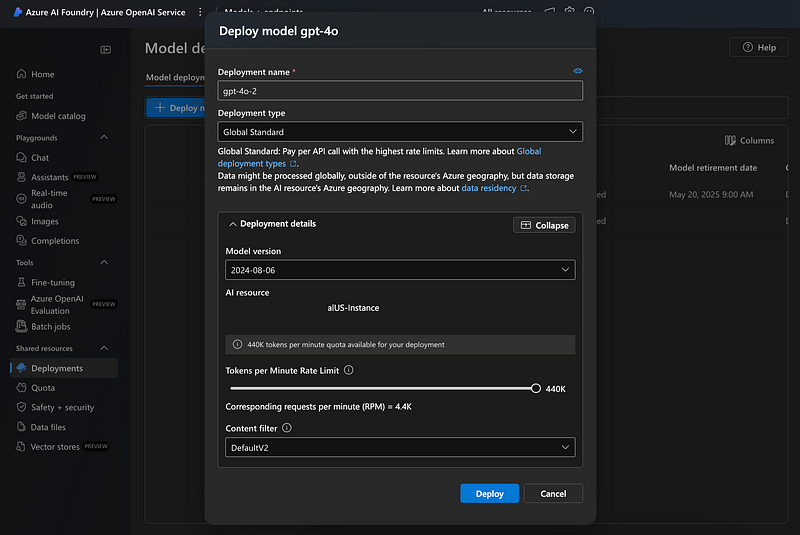
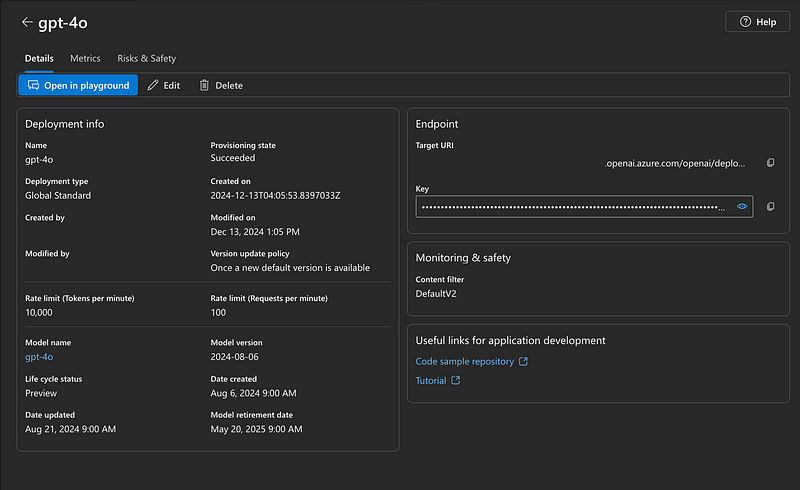
Tokens Per Minute Rate Limit
- Definition: Specifies the total number of tokens (input + output) that can be processed in a minute.
- Example: A rate limit of
10,000 tokens per minutemeans that the sum of all tokens in API requests and responses cannot exceed 10,000 in one minute. This limit ensures resource availability and fairness among users. - Usage: Ensure your use case aligns with this limit to avoid throttling. Planning workloads around these limits can help achieve consistent performance.
Rate Limit (Requests Per Minute)
- Definition: The maximum number of API requests that can be made in a minute.
- Example: If the token limit is
10,000 tokens per minuteand each request uses 100 tokens, you can make up to 100 requests per minute. However, combining both token and request limits helps manage usage efficiently.
Corresponding Tokens Per Request Limit
- Definition: The maximum number of tokens allowed in a single request (input + output).
- Common Limits: 8,000 tokens or 32,000 tokens, depending on the model. Adjusting this ensures that large or complex queries don’t exceed allocated resources.
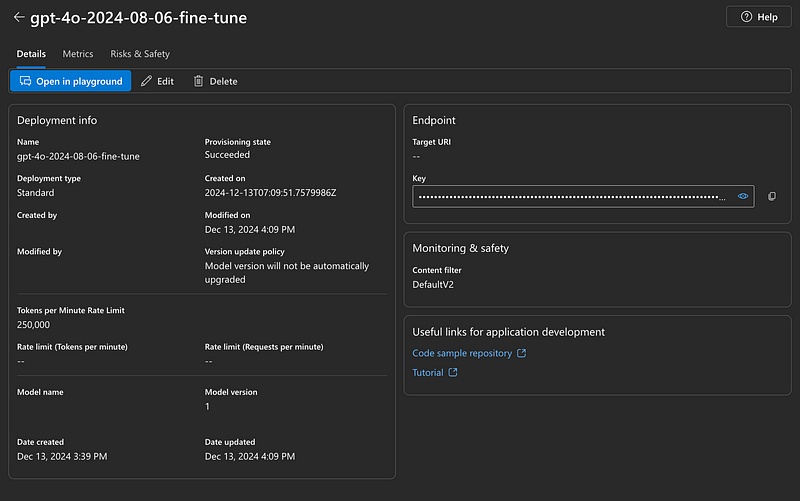
2. Fine-Tuning Parameters
Fine-tuning allows you to adapt a base GPT model to specific tasks or datasets. Azure’s fine-tuning process includes several customizable parameters that impact the training process. Each parameter ensures that fine-tuning is as effective and resource-efficient as possible.
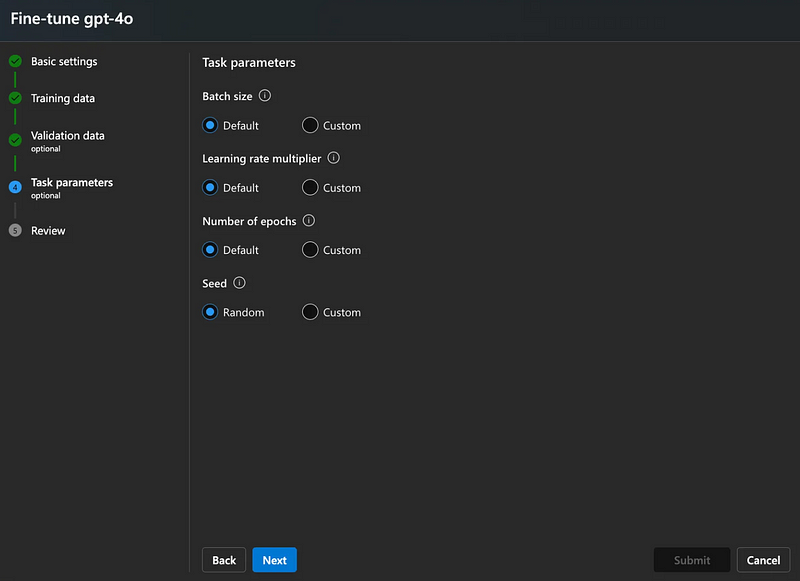
Batch Size
- Definition: The number of data samples processed in one training iteration.
- Default: Automatically selected based on system optimization.
- Custom: User-specified batch size. Larger sizes improve speed but require more memory. Smaller sizes can lead to slower but more precise model adjustments.
Learning Rate Multiplier
- Definition: A scaling factor applied to the base learning rate to control the update step size during training.
- Default: Pre-configured optimal multiplier.
- Custom: Specify a value to adjust learning speed. Fine-tuning often requires lower rates to avoid overshooting the optimal parameter values.
Number of Epochs
- Definition: The number of complete passes through the training dataset.
- Default: Automatically determined based on dataset size.
- Custom: Specify the desired number of epochs. While more epochs may refine performance, too many can lead to overfitting, especially with smaller datasets.
Seed
- Definition: A value used to initialize randomization, ensuring reproducibility of results.
- Options:
- Random: Randomly initializes each training run.
- Custom: Use a fixed value to replicate results in future runs, which is helpful for scientific or industrial experiments.
3. Decoding Parameters and Tokens
Decoding Parameters
Decoding Parameters provide an interactive environment to test GPT models with adjustable parameters. These allow real-time adjustments to control the style and nature of the generated outputs, offering flexibility without the need for fine-tuning.
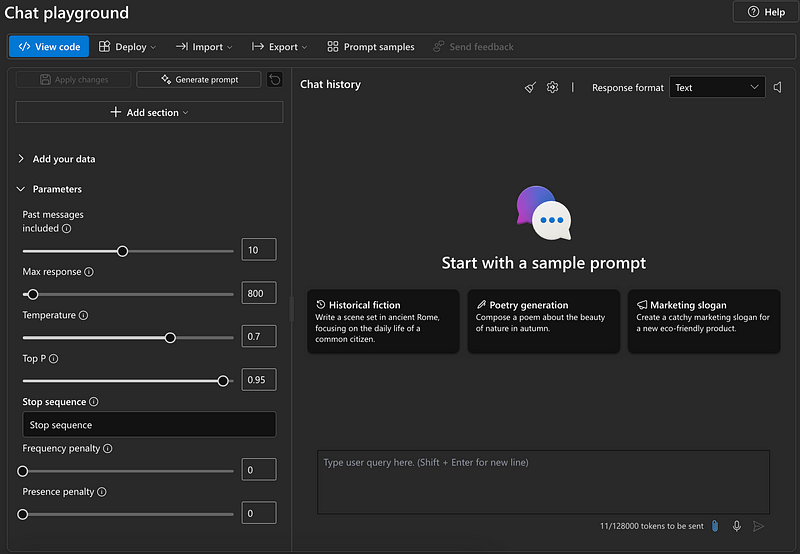
Max Response (Tokens)
- Definition: The maximum number of tokens the model can generate in a single response.
- Default: 800 tokens.
- Tip: Adjust based on your use case. Longer responses require higher token limits but consume more resources. Setting an appropriate limit ensures a balance between efficiency and completeness.
Temperature
- Definition: Controls the randomness of the model’s responses.
- Low Values (e.g., 0.2): Deterministic and focused outputs. This setting is ideal for generating factual or structured responses.
- High Values (e.g., 0.8): Creative but less consistent responses, which are better suited for brainstorming or creative writing tasks.
Top P
- Definition: Nucleus sampling parameter that limits the model’s token selection to a cumulative probability.
- 1.0: Considers all tokens.
- 0.95: Focuses on the most probable tokens, filtering out less likely continuations. This parameter is essential for controlling the variety of outputs.
Frequency Penalty
- Definition: Penalizes repeated tokens to reduce redundancy.
- Range: 0 (no penalty) to 1 (high penalty). Useful for ensuring variety in the generated content.
Presence Penalty
- Definition: Encourages or discourages new topics in responses.
- Range: 0 (no effect) to 1 (strongly encourages new topics). This is particularly useful for exploratory dialogues.
Stop Sequence
- Definition: A specific sequence that stops the model’s output generation.
- Example: Setting a newline (
\\n) as a stop sequence halts generation after a line break. This ensures precise and controlled outputs in structured tasks.
Past Messages Included
- Definition: The number of previous messages retained in context for generating a response.
- Default: 10 messages.
- Tip: Higher values improve contextual awareness but consume more tokens. Adjusting this can improve conversational coherence.
Decoding Parameters vs Fine-Tuning
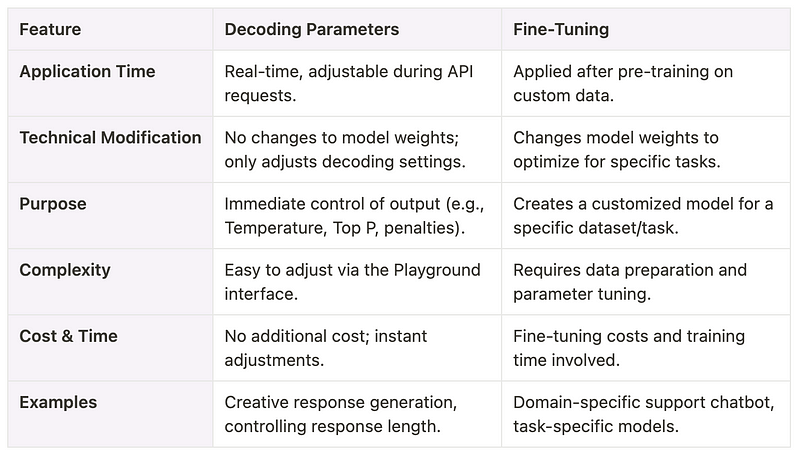
How Are Decoding Parameters Used?
Decoding Parameters provide real-time control over model outputs. Here are some key parameters and their use cases:
Temperature: Controls output creativity and randomness.
- Example: A higher Temperature produces more creative responses, while a lower value generates consistent, factual outputs. This is particularly helpful in toggling between exploratory and precise tasks.
Top P: Limits token selection based on cumulative probability.
- Example: Setting Top P=0.95 focuses on the most likely 95% of tokens, ensuring high-quality outputs without unnecessary randomness.
Max Response: Restricts the maximum length of generated responses, ensuring efficient use of resources and concise outputs.
Frequency Penalty & Presence Penalty: Adjust repetition and encourage new topics in responses. These parameters are essential for maintaining conversational flow and avoiding redundancy.
Understanding Token Counts on Chat Playground
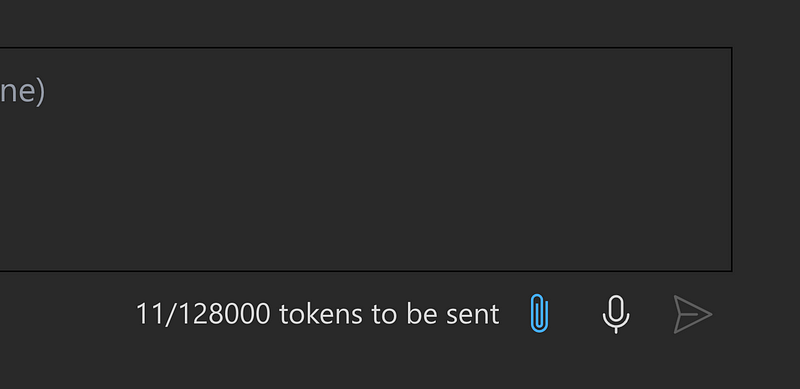
In the context of token usage, numbers like 11/128,000 tokens provide the following information:
11 tokens:
- This represents the total tokens used so far in the current request, including both input tokens (e.g., the prompt or instruction) and any system-generated tokens.
- For example, a prompt like “Hello, how are you?” might use around 6–7 tokens, and additional system or configuration messages bring the total to 11 tokens.
128,000 tokens:
- This is the maximum number of tokens allowed for a single request, including both input tokens and the tokens in the model’s response.
- Such a high limit is rare and may suggest a customized configuration provided by Azure for specific deployments or unique use cases. Typically, GPT models allow 8,000 or 32,000 tokens per request.
Practical Importance
- Real-Time Token Management: Ensure that the sum of input and output tokens does not exceed the set maximum (e.g., 128,000 tokens). If you use 11 tokens for input, the model can generate up to 127,989 tokens in its response.
- Resource Efficiency: Plan prompts and expected outputs to optimize performance and stay within limits, especially when working with long-form or detailed content.
Conclusion
Decoding Parameters are a simple and quick way to adjust a model’s output style in real-time, while Fine-Tuning creates a deeply optimized model for specific tasks. Both approaches are complementary: Fine-Tune to create a tailored model and use Decoding Parameters to fine-tune the output on the fly. By leveraging these tools effectively, Azure OpenAI Service enables you to deploy, fine-tune, and interact with GPT models for a wide range of applications, ensuring efficiency, scalability, and optimal results. With the right balance of these techniques, users can achieve high performance while maintaining flexibility and control over their AI-driven tasks.