IMG2TEXT-Part1. Background (Stable Diffusion, CLIP, Prompt)
In this article, I’d like to talk about background information to implement CLIPInterrogator+OFA+ViT_LB0.568. Part 2 will cover the…

In this article, I’d like to talk about background information to implement CLIPInterrogator+OFA+ViT_LB0.568. Part 2 will cover the implementation of this notebook. You can check the part 2 from my medium.
1. About the Competition
The goal of this competition is to develop a text-to-image model that can predict the text prompt that generated a given image, rather than generating an image from a text prompt. The dataset contains (prompt, image) pairs generated by Stable Diffusion 2.0. The purpose of the competition is to understand how reversible the latent relationship is between prompts and images. The competition challenges participants to create a model that can reliably invert the diffusion process used to generate the images. The prompt similarity will be calculated using embeddings, and participants have the freedom to model the embeddings directly or first predict prompts and then convert them to embeddings. The aim of the competition is to create high-quality models using robust cross-validation techniques.
2. Background Information
2–1. Language Generation
🪙 Token and Tokenizer
(1) Token
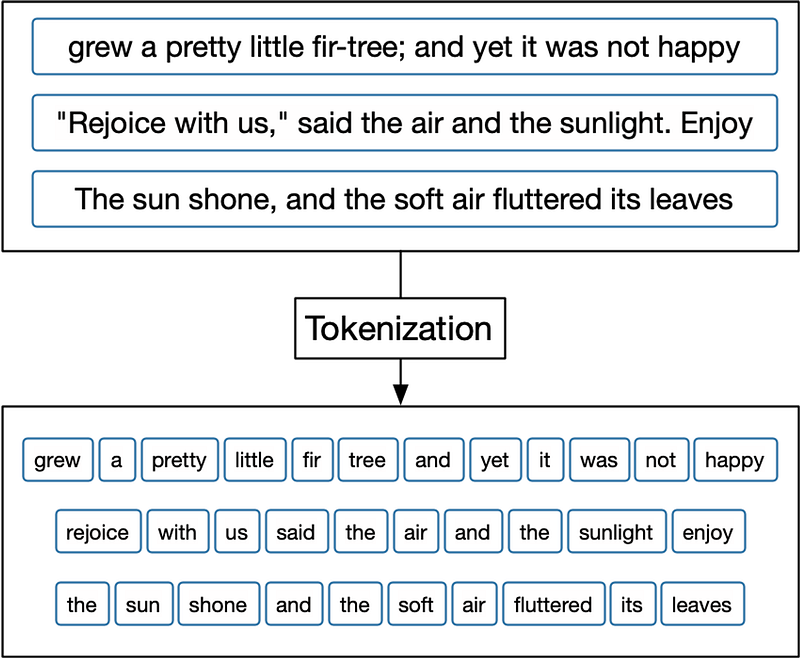
A token refers to a sequence of characters representing a meaningful unit. A sequence of tokens is a sequence of individual elements that are treated as discrete units Here are some examples of sequences of tokens:
- “The quick brown fox jumps over the lazy dog”
- Tokens: “The”, “quick”, “brown”, “fox”, “jumps”, “over”, “the”, “lazy”, “dog”
- “I like to eat pizza for dinner”
- Tokens: “I”, “like”, “to”, “eat”, “pizza”, “for”, “dinner”
- “John and Jane went to the park”
- Tokens: “John”, “and”, “Jane”, “went”, “to”, “the”, “park”
- “He is a computer science student at a university in Tokyo”
- Tokens: “He”, “is”, “a”, “computer”, “science”, “student”, “at”, “a”, “university”, “in”, “Tokyo”
(2) Tokenizer
In natural language processing, a tokenizer is a tool used to break down text into smaller units, usually words or subwords. The OFATokenizer is a tokenizer specifically designed for OpenAI’s GPT models, including GPT-3, which uses byte-pair encoding (BPE) to split words into subwords.
BPE is a data compression technique that replaces frequently occurring sequences of characters with a single symbol, allowing for the representation of many words as combinations of subwords. The OFATokenizer implements BPE and also includes various other features such as padding, truncation, and conversion of tokens to input IDs required for feeding data into the GPT models.
🏹 Prompt and Embedding
(1) Prompt
- In natural language processing, a prompt is a piece of text that is used to guide a language model to generate text that is relevant to a specific task. It is a way to provide context or a specific goal for the model to focus on when generating output.
- Here are some examples of prompts:
- Prompt for a language translation task: “Translate the following sentence from English to French: ‘I love to eat pizza.’”
- Prompt for a text completion task: “Complete the following sentence: ‘The capital of France is ________.’”
- Prompt for a question-answering task: “What is the capital city of Spain?”
- Prompt for a sentiment analysis task: “Analyze the sentiment of the following tweet: ‘Just had the best day ever at the beach! #happy’”
- Prompt for a text generation task: “Write a short story about a boy who discovers a magic key that unlocks a secret door.”
In each of these examples, the prompt provides specific guidance or context for the language model to produce output that is relevant to the given task.
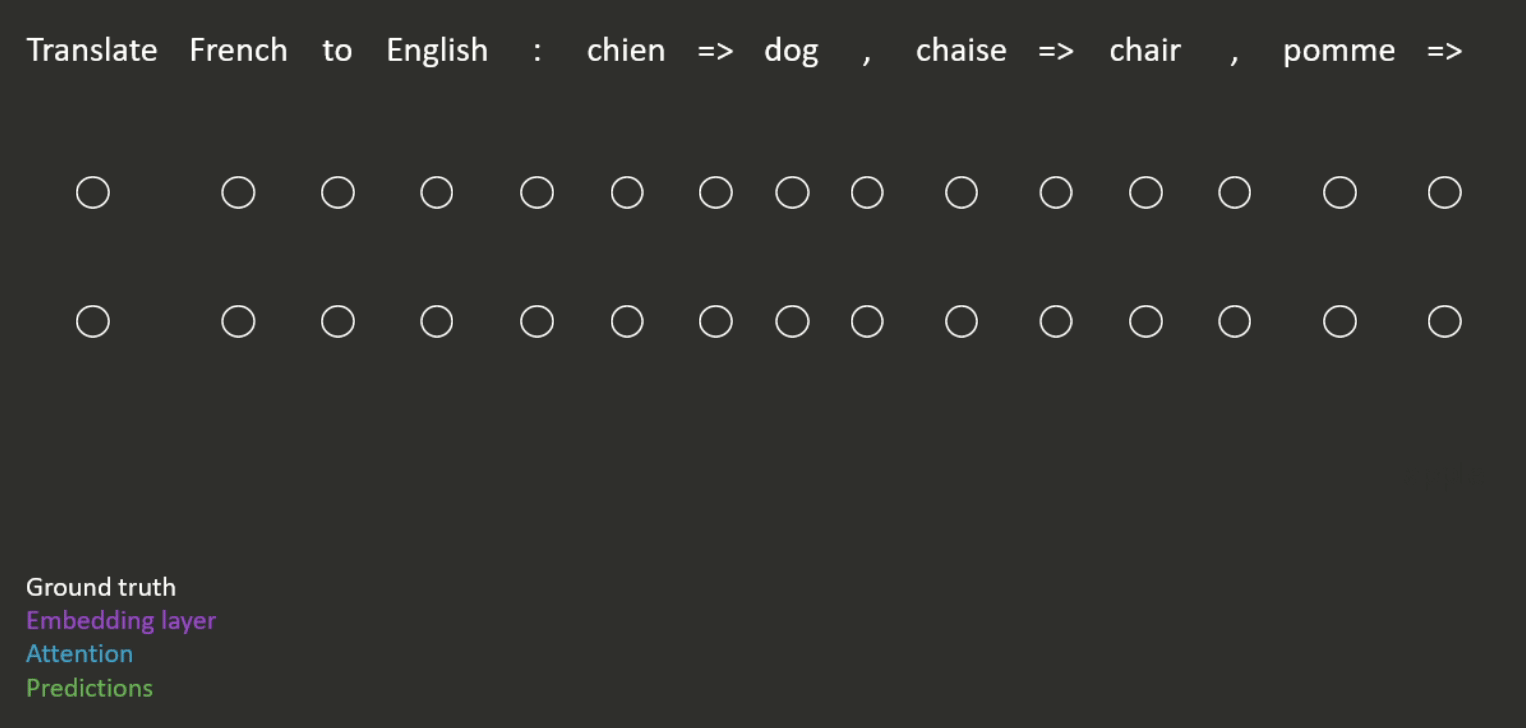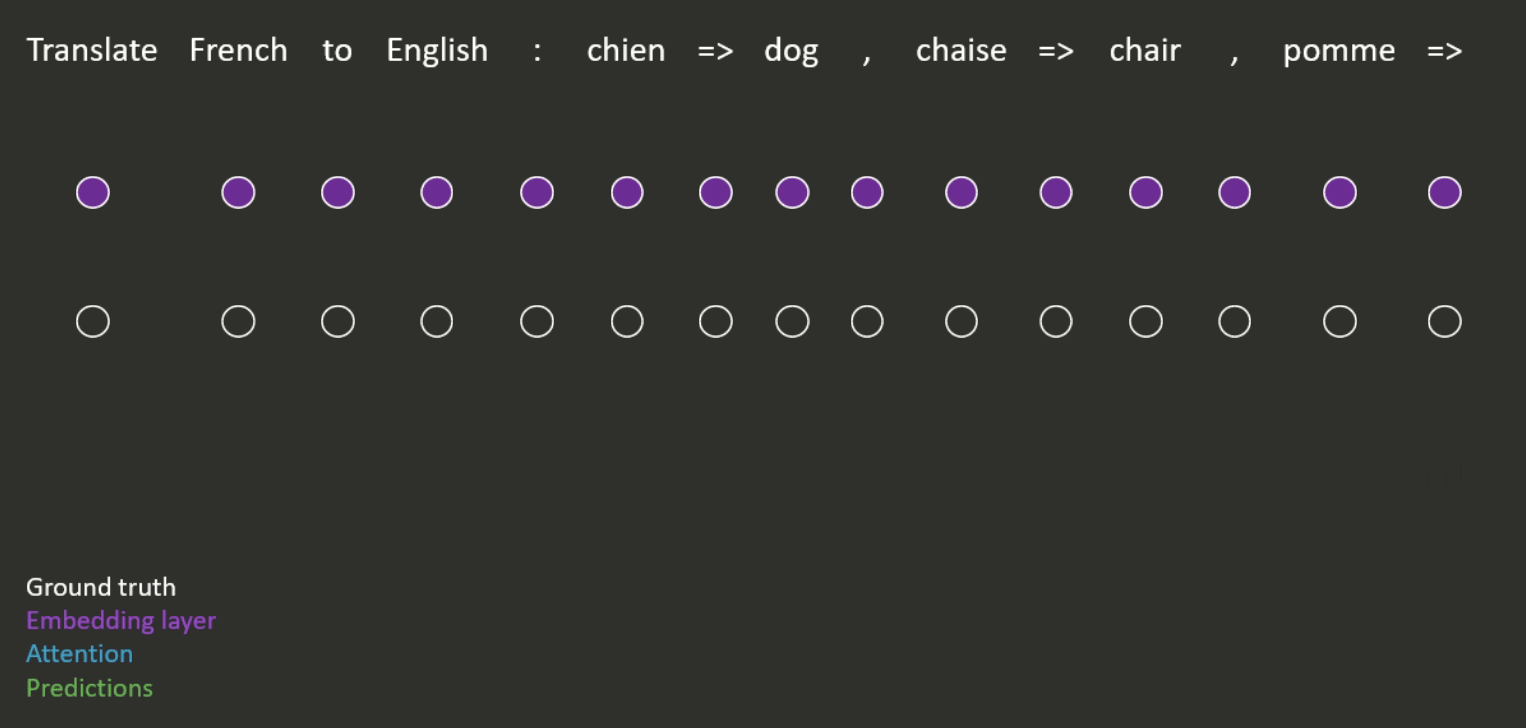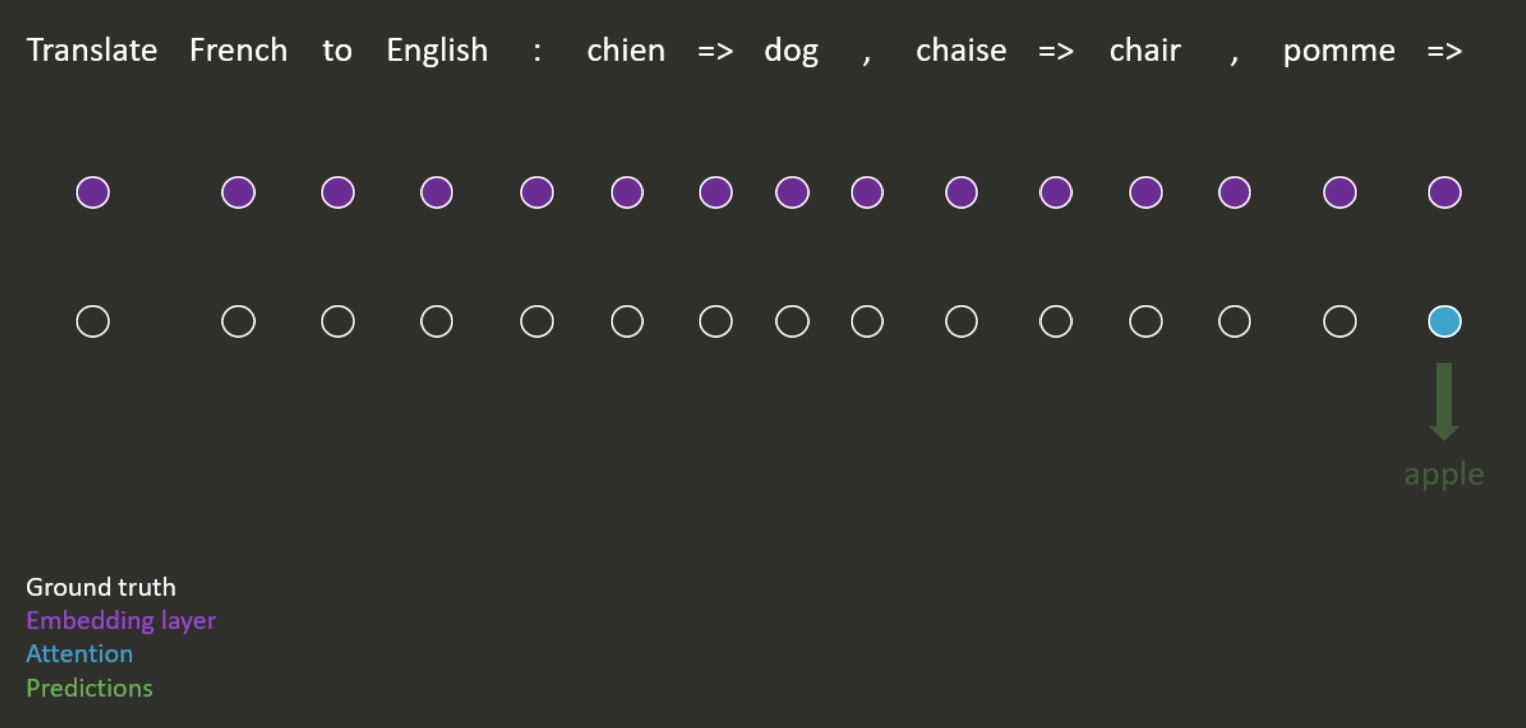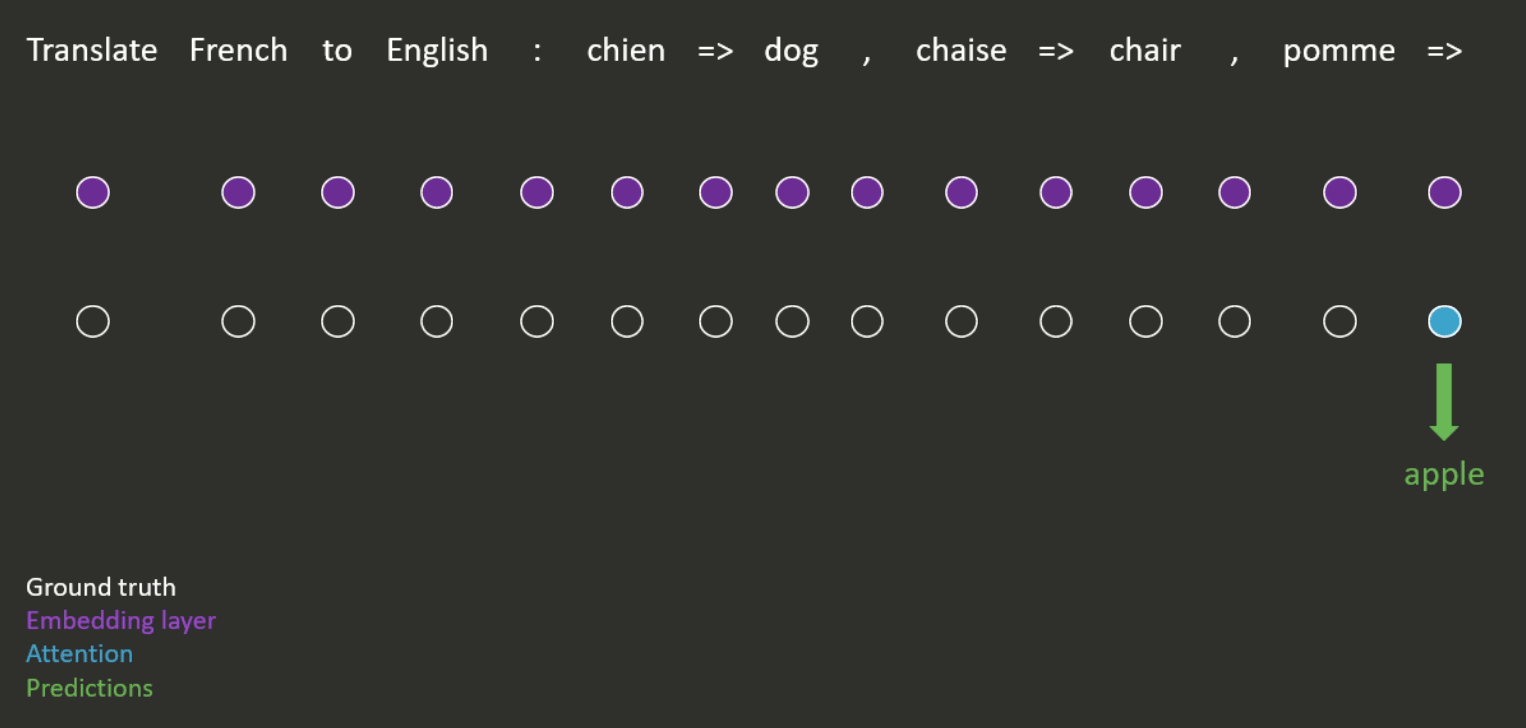
(2) Prompt Embedding

Prompt embeddings are a type of representation of textual input that can be used as input to a machine-learning model. These embeddings are generated by encoding the text input using a pre-trained language model, such as GPT or BERT, which maps the input text to a dense, fixed-length vector representation.
Suppose we want to generate a realistic image of a new type of person. We can provide a prompt, such as “A person half Yoda half Gandalf.” The prompt is then converted into a sequence of tokens, which is used as input to the pre-trained language model.
The language model will then generate a sequence of embeddings for each token in the prompt, which captures the meaning of the text. These embeddings are then combined to form a single Prompt Embedding, which represents the entire prompt.
The Prompt Embedding is then fed into an image generation model, which uses it to generate a realistic image of a person who is half Yoda and half Gandalf. We can generate images of different objects, scenes, and styles by providing different prompts.
🔦 Beam Search
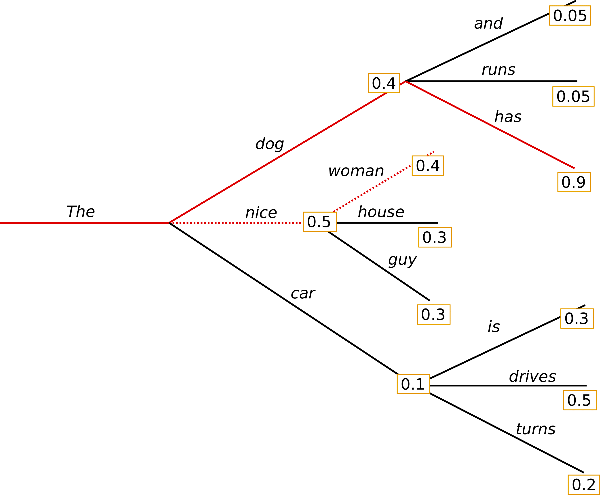
Beam search is a heuristic search algorithm used in natural language processing (NLP) and other areas of artificial intelligence. It is commonly used to generate sequences of text, such as sentences or paragraphs, based on a language model.
num_beams is a parameter used in some language generation models, such as GPT-2 and T5, to control the beam search during decoding. Beam search is an algorithm used to generate a sequence of tokens, where at each step, the model generates a set of candidates and keeps the top k candidates, where k is the beam size. The candidates are then extended with all possible next tokens, and the top k candidates are selected again, and the process repeats until the desired sequence length is reached or an end-of-sequence token is generated.
num_beams specifies the number of beams used in beam search decoding. Increasing num_beams typically results in better-quality generations at the cost of increased computation time. However, using too many beams can lead to repetitive or overly conservative generations, while using too few beams can lead to less diverse or less accurate generations.
🪺 N-grams
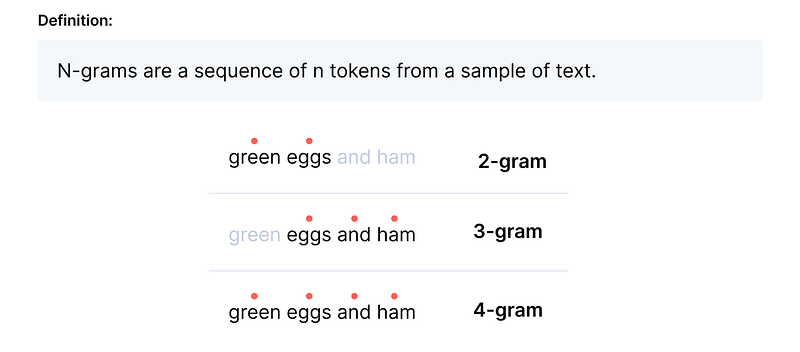
n-gram refers to the number of contiguous words that should not be repeated in the generated captions. Here are the examples of n-grams from n=1 to n=4 for the sentence “green eggs and ham”:
- n=1 (unigrams): [“green”, “eggs”, “and”, “ham”]
- n=2 (bigrams): [“green eggs”, “eggs and”, “and ham”]
- n=3 (trigrams): [“green eggs and”, “eggs and ham”]
- n=4 (four-grams or quadgrams): [“green eggs and ham”]
When we call model.generate() function, no_repeat_ngram_size is used, which is a parameter used in text generation tasks to prevent the model from generating repeated n-grams in its output. It specifies the size of the largest n-gram window that is disallowed from being repeated. For example, if no_repeat_ngram_size=2, the model will prevent the generation of any bigram (2-gram) that has already appeared in the generated text. This can help to make the generated text more diverse and less repetitive.
2–2. Models
🖼 Stable Diffusion
(1) Diffusion

Diffusion is a concept in machine learning that refers to a stochastic process of progressively adding noise to a given input signal to generate diverse samples that are similar to the input. In the context of image generation, diffusion models add noise to a latent space representation and then propagate this noise through the model to generate a new observation. By repeating this process multiple times and sampling different latent representations, the model can generate diverse images that capture the different variations in the data.
(2) Stable Diffusion
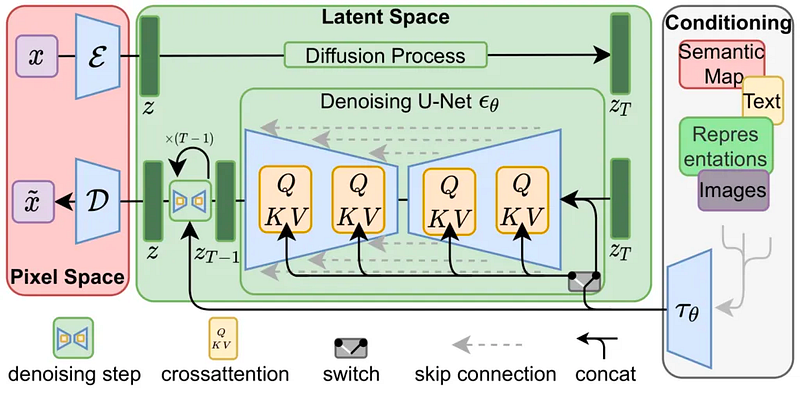
Stable Diffusion 2.0 is a state-of-the-art implementation of the diffusion process for text-to-image generation, developed by OpenAI. This method is designed to handle the challenges associated with generating high-quality images from textual prompts, including the high dimensionality of the image space and the need to capture the diversity of image variations that correspond to a given text prompt.
The Stable Diffusion Architecture consists of Autoencoder, U-Net, and Text Encoder.
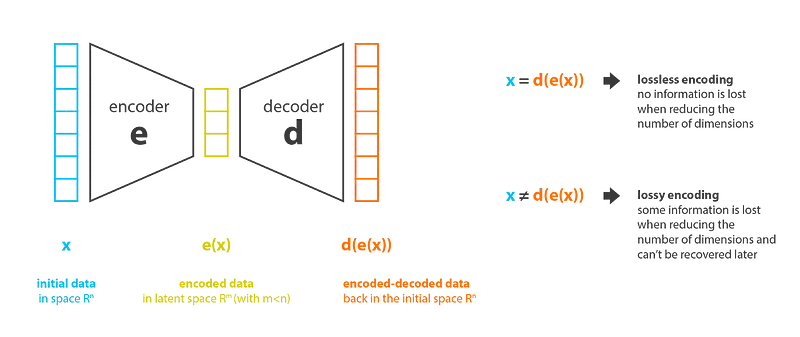
- Autoencoder: It is responsible for compressing and reconstructing the image input. It is a variational autoencoder (VAE), which means that it learns a latent representation of the input distribution by modeling the data’s underlying probability distribution. This allows for the generation of new images that closely resemble the input images.
- U-Net: It takes the reconstructed image from the Autoencoder and refines it by performing a series of convolutional operations. This results in a high-quality image output that accurately represents the input image.
- Text Encoder: A frozen CLIP ViT-L/14 Text Encoder is used for Stable Diffusion. It encodes the text into a latent space that can be used to condition the generation of the image, ensuring that the output image is aligned with the user’s intentions.
☝️ OFA
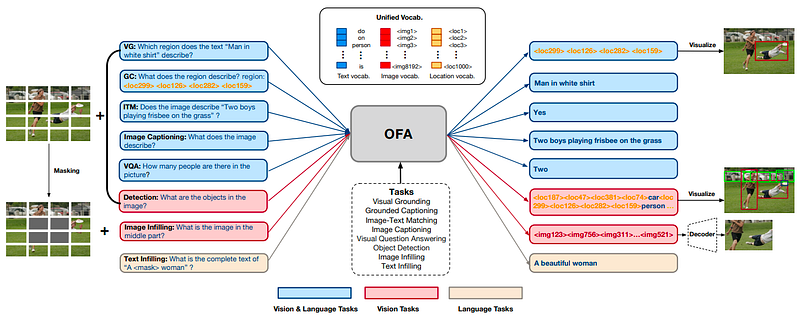
OFA model (ICML 2022) serves as a unified and versatile pre-trained model that can effectively transfer to numerous downstream tasks across different domains and modalities. You can check out their github and paper.
🎨 CLIP and CLIP interrogator tool
(1) CLIP
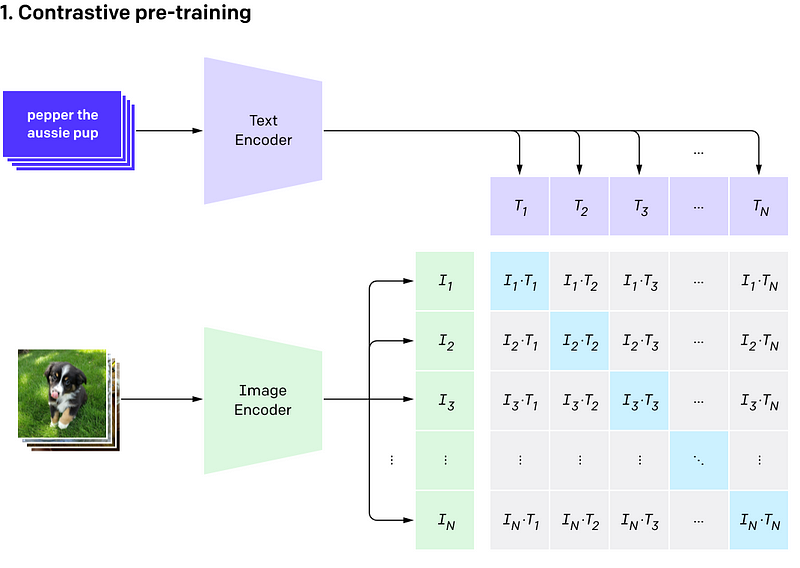
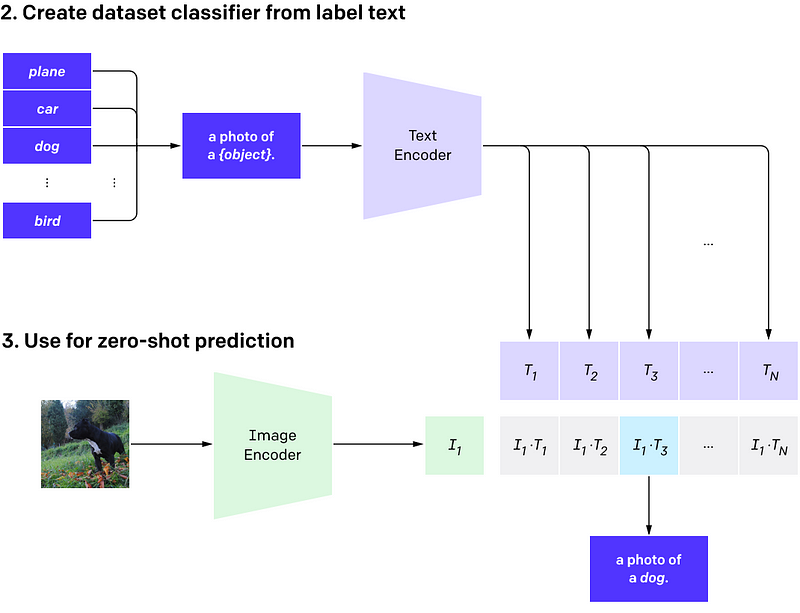
CLIP (Contrastive Language-Image Pre-Training) is a state-of-the-art deep learning model developed by OpenAI that learns to associate images and text in a way that enables it to perform a wide range of tasks, including image and text classification, image generation, and natural language processing. CLIP is trained on a massive dataset of images and their associated captions, as well as a large corpus of text from the internet.
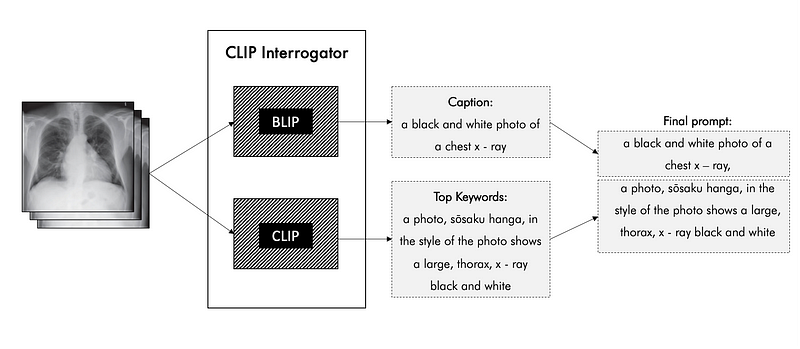
(2) CLIP Interrogator
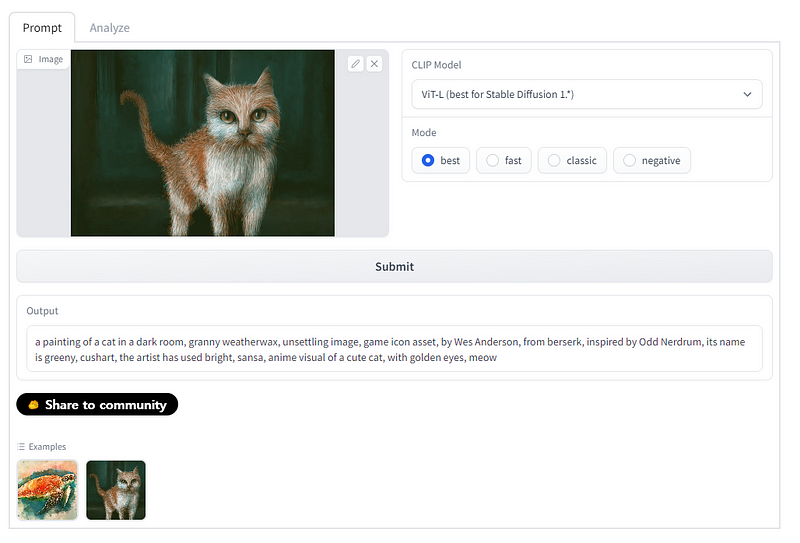
The CLIP Interrogator is a prompt engineering tool that combines OpenAI’s CLIP and Salesforce’s BLIP to optimize text prompts to match a given image. It provides prompt outputs to generate images using generative models such as Stable Diffusion.
The CLIP Interrogator pipeline works as follows:
- An image is passed to the input to BLIP to obtain the main description.
- An image is passed to the input to CLIP to receive its embedding.
- Embeddings received from the image are compared with embeddings received from labels from the lists and the top 4 with the greatest similarity are selected.
- There are 4 main lists on which the outgoing prompt for the CLIP part is formed: artists.txt (list with artists), flavors.txt (main list for image description), mediums.txt (image type), movements.txt (image style) and sites (popular artwork sites).
- The resulting texts are concatenated and returned as an image description (or prompt on which an image was generated).
Therefore, in the CLIP Interrogator, the BLIP model is used for captioning, while the CLIP model serves as a multimodal model that associates images with text descriptions. Both models are used to improve the quality of the prompt that best matches the image.
🔄 SentenceTransformers
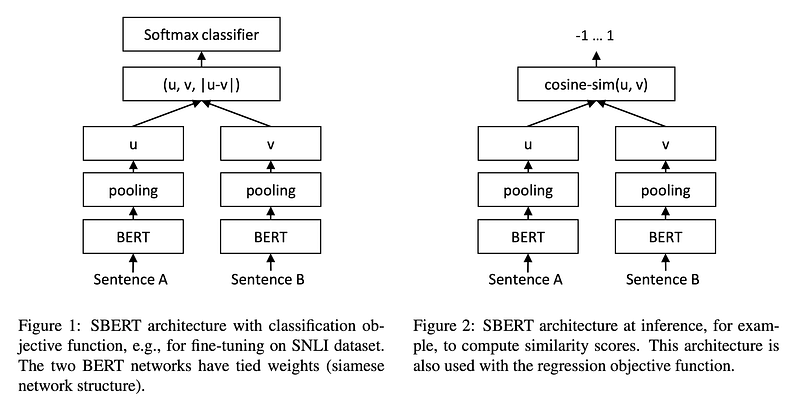
SentenceTransformers is a Python framework for state-of-the-art sentence, text and image embeddings. The framework creates text embeddings for 100+ languages that can be compared to find similar meanings. Helpful for tasks like semantic search and paraphrase mining.
In this competition, MiniLM is being used by the SentenceTransformer to generate sentence embeddings.
2–3. Dataset
🏅 Competition Dataset
stable-diffusion-image-to-prompts
The task is to predict the prompts used to generate target images, which were created using Stable Diffusion 2.0 with various methods and range from simple to complex. The images were generated with 50 steps at 768x768 px and then downsized to 512x512 for the competition dataset.
images: 7 files (512x512, PNG)prompts.csv: prompts that were used to create the image samples (7 rows)sample_submission.csv: Embeddings of the prompts in the prompts.csv (384x7=2688 rows)
It is used in Calculating Stable Diffusion Prompt Embeddings.
sentence-transformers: The framework that can generate sentence or text embeddingsall-MiniLM-L6-v2: all-MiniLM-L6-v2 is a pre-trained language model available in the SentenceTransformers library, which is used by the SentenceTransformer to generate sentence embeddings.
☝️ OFA
transformers-4.18.0.dev0-py3-none-any.whl: It is a wheel file that contains a specific version of the Transformers library.OFA-large-caption: It will be used for OFATokenizer.
🎨 Clip Interrogator
model_large_caption.pthis pre-trained blip_model. blip_model is used for image processing.CLIP-ViT-H-14-laion2B-s32B-b79K/open_clip_pytorch_model.binis a pre-trained clip_model. For the best prompts, Stable Diffusion 2.0 uses ViT-H-14/laion2b_s32b_b79k
clip_interrogator-0.4.3-py3-none-any.whlis the code and resources necessary to install the clip_interrogator package.
✌️ ViT
vit_large_patch16_384_1_64_0.0001_0.6564.pthis the saved weights are used for ViT prediction function
stable-diffusion-vit-baseline-train
vit_base_patch16_224.pthis loaded using the predict function along with other parameters such as images, input_size1, and batch_size to generate embeddings for the given input images.
3. Evaluation & Submission
3–1. Submission File
Submissions are assessed based on the cosine similarity score between predicted and actual prompt embeddings. The submission file must predict prompts and convert them into 384-length embedding vectors for each image in the test set, with a header and format of imgId_eId.
imgId_eId,val
20057f34d_0,0.018848453
20057f34d_1,0.030189732
....
20057f34d_383,-0.007934112
227ef0887_0,0.017384542
etc.3–2. How to make a sample submission
Imports
You must attach the sentence-transformers-2.2.2 dataset in order to correctly create embeddings of your predicted prompts. Sentence-transformers-2.2.2 is a Python library for state-of-the-art sentence, text, and image embeddings using pre-trained models such as BERT, RoBERTa, XLM-R, and more. It allows for efficient similarity search and clustering of large datasets using a variety of methods, including cosine similarity and k-means clustering. The library also includes methods for fine-tuning pre-trained models on new datasets and tasks.
import os
import sys
import numpy as np
import pandas as pd
from pathlib import Path
sys.path.append('../input/sentence-transformers-222/sentence-transformers')
from sentence_transformers import SentenceTransformer, models
comp_path = Path('/kaggle/input/stable-diffusion-image-to-prompts/')Load the Sample Submission
sample_submission = pd.read_csv(comp_path / 'sample_submission.csv', index_col='imgId_eId')
sample_submission.head()
'''
imgId_eId val
20057f34d_0 0.018848
20057f34d_1 0.030190
20057f34d_2 0.072792
20057f34d_3 -0.000673
20057f34d_4 0.016774
'''Build index from images, compare to Sample Submission index
A list of image IDs and embedding IDs is created to be used in the submission file. The image IDs are obtained by reading the filenames in the ‘images’ folder, and the embedding IDs are generated using a range. The resulting list of pairs of image ID and embedding ID is then checked to make sure it matches the index of the sample submission file. The length of the embedding vector used is set to 384.
images = os.listdir(comp_path / 'images')
imgIds = [i.split('.')[0] for i in images]
EMBEDDING_LENGTH = 384
eIds = list(range(EMBEDDING_LENGTH))
imgId_eId = [
'_'.join(map(str, i)) for i in zip(
np.repeat(imgIds, EMBEDDING_LENGTH),
np.tile(range(EMBEDDING_LENGTH), len(imgIds)))]
assert sorted(imgId_eId) == sorted(sample_submission.index)Load the embedding model
We load the pre-trained SentenceTransformer model named “all-MiniLM-L6-v2” which refers to a pre-trained language model architecture developed by the Hugging Face team. It is a transformer-based language model that uses the same architecture as GPT-3, but with fewer parameters. The “L6” in the name refers to the number of layers in the model. The MiniLM models were designed to be more computationally efficient and require less memory than larger transformer models while still maintaining high performance on various natural language processing tasks.
st_model = SentenceTransformer('/kaggle/input/sentence-transformers-222/all-MiniLM-L6-v2')Create a sample submission with a constant prompt prediction
The st_model.encode() method is then used to generate embeddings of the prompts, which are flattened into a 1D array. The flattened embeddings are organized in a DataFrame with the index as the image ID concatenated with the embedding ID (imgId_eId), and the embeddings as values (val). This DataFrame matches the required format for the submission file.
prompts = ['All work and no Kaggle makes Jack a dull boy'] * len(images)
prompt_embeddings = st_model.encode(prompts).flatten()
submission = pd.DataFrame(
index=imgId_eId,
data=prompt_embeddings,
columns=['val']).rename_axis('imgId_eId')In Part 2, we will delve into models and prompt predictions. Thank you for reading!