Introduction
The FLEURS (Few-shot Learning Evaluation of Universal Representations of Speech) dataset represents a groundbreaking advancement in multilingual speech recognition research. Developed by Google, this comprehensive dataset provides high-quality speech data across 102 languages, making it an invaluable resource for researchers and practitioners working on multilingual automatic speech recognition (ASR) systems.
What is FLEURS?
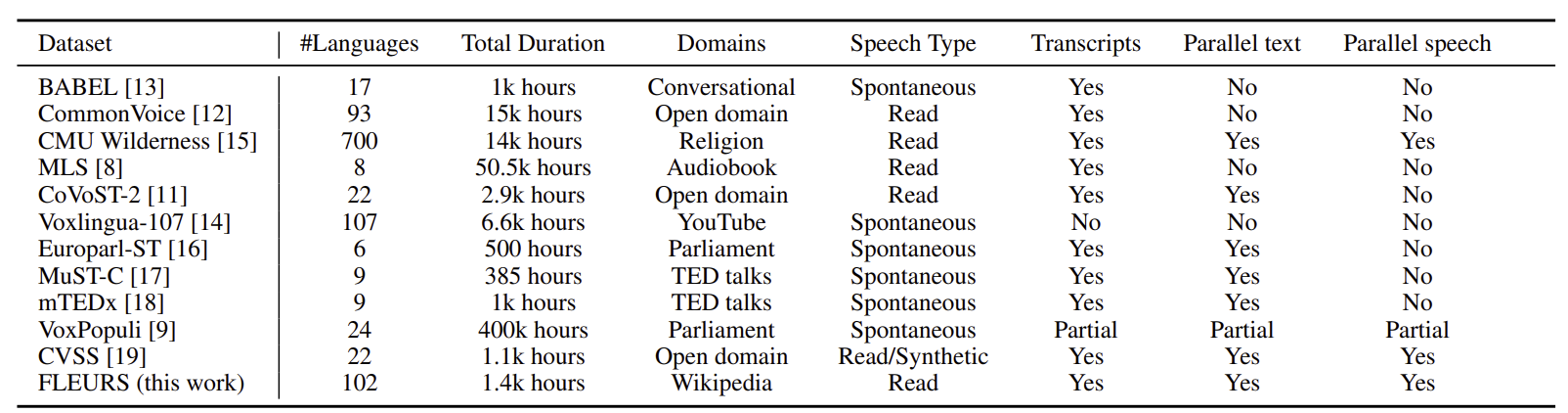
FLEURS is a multilingual speech dataset that extends the FLoRes machine translation benchmark to the speech domain. It contains approximately 10-12 hours of speech data per language, totaling over 1,000 hours of multilingual speech content. The dataset is built upon 2,009 n-way parallel sentences from the FLoRes dev and devtest sets, ensuring consistency across languages.
Key Statistics
| Metric | Value |
|---|
| Total Languages | 102 |
| Total Speech Hours | 1,000+ |
| Hours per Language | 10-12 |
| Parallel Sentences | 2,009 |
| License | CC-BY-4.0 |
| Sampling Rate | 16 kHz |
| Audio Format | WAV |
| Channels | Mono |
Dataset Structure
Data Fields
Each data instance in FLEURS contains the following fields:
| Field | Type | Description |
|---|
id | int | Unique identifier for the audio sample |
num_samples | int | Number of audio samples |
path | str | Path to the audio file |
audio | dict | Audio object with array, sampling rate, and path |
raw_transcription | str | Non-normalized transcription |
transcription | str | Normalized transcription text |
gender | int | Gender class ID (0/1) |
lang_id | int | Language class ID |
language | str | Language name |
lang_group_id | int | Geographic language group ID |
Data Splits
| Split | Sentences | Duration | Purpose |
|---|
| Train | ~1,500 | ~10 hours | Model training |
| Validation | ~150 | ~1 hour | Hyperparameter tuning |
| Test | ~350 | ~2 hours | Final evaluation |
Language Coverage
FLEURS organizes languages into seven geographic regions:
Western Europe (25 languages)
| Language Code | Language | Language Code | Language |
|---|
en_us | English | fr_fr | French |
de_de | German | es_es | Spanish |
it_it | Italian | pt_pt | Portuguese |
nl_nl | Dutch | sv_se | Swedish |
da_dk | Danish | no_no | Norwegian |
fi_fi | Finnish | is_is | Icelandic |
el_gr | Greek | hu_hu | Hungarian |
pl_pl | Polish | cs_cz | Czech |
sk_sk | Slovak | sl_si | Slovenian |
hr_hr | Croatian | sr_rs | Serbian |
bg_bg | Bulgarian | ro_ro | Romanian |
et_ee | Estonian | lv_lv | Latvian |
lt_lt | Lithuanian | mt_mt | Maltese |
cy_gb | Welsh | ga_ie | Irish |
ca_es | Catalan | gl_es | Galician |
ast_es | Asturian | oc_fr | Occitan |
bs_ba | Bosnian | kea_cv | Kabuverdianu |
lb_lu | Luxembourgish | | |
Eastern Europe (16 languages)
| Language Code | Language | Language Code | Language |
|---|
ru_ru | Russian | uk_ua | Ukrainian |
be_by | Belarusian | hy_am | Armenian |
ka_ge | Georgian | mk_mk | Macedonian |
sq_al | Albanian | eu_es | Basque |
tr_tr | Turkish | az_az | Azerbaijani |
kk_kz | Kazakh | ky_kg | Kyrgyz |
uz_uz | Uzbek | tg_tj | Tajik |
mn_mn | Mongolian | he_il | Hebrew |
ar_eg | Arabic | fa_ir | Persian |
ps_af | Pashto | ckb_iq | Sorani Kurdish |
Sub-Saharan Africa (19 languages)
| Language Code | Language | Language Code | Language |
|---|
af_za | Afrikaans | am_et | Amharic |
sw_ke | Swahili | yo_ng | Yoruba |
ig_ng | Igbo | ha_ng | Hausa |
zu_za | Zulu | xh_za | Xhosa |
sn_zw | Shona | lg_ug | Ganda |
om_et | Oromo | so_so | Somali |
ff_sn | Fula | wo_sn | Wolof |
umb_ao | Umbundu | ln_cd | Lingala |
luo_ke | Luo | kam_ke | Kamba |
nso_za | Northern Sotho | ny_mw | Nyanja |
South Asia (14 languages)
| Language Code | Language | Language Code | Language |
|---|
hi_in | Hindi | bn_bd | Bengali |
ur_pk | Urdu | ta_in | Tamil |
te_in | Telugu | kn_in | Kannada |
ml_in | Malayalam | gu_in | Gujarati |
mr_in | Marathi | pa_in | Punjabi |
as_in | Assamese | or_in | Oriya |
ne_np | Nepali | sd_pk | Sindhi |
South-East Asia (11 languages)
| Language Code | Language | Language Code | Language |
|---|
vi_vn | Vietnamese | th_th | Thai |
id_id | Indonesian | ms_my | Malay |
tl_ph | Filipino | ceb_ph | Cebuano |
jv_id | Javanese | km_kh | Khmer |
lo_la | Lao | my_mm | Burmese |
mi_nz | Maori | | |
CJK Languages (4 languages)
| Language Code | Language | Language Code | Language |
|---|
zh_cn | Chinese (Simplified) | yue_hk | Cantonese |
ja_jp | Japanese | ko_kr | Korean |
Usage Examples
Basic Loading
# Basic FLEURS dataset loading
# Source: Hugging Face datasets library documentation
from datasets import load_dataset
# Load specific language
fleurs = load_dataset("google/fleurs", "ko_kr", split="train")
# Load all languages for multilingual training
fleurs_all = load_dataset("google/fleurs", "all")
# Streaming mode for large datasets
fleurs_streaming = load_dataset("google/fleurs", "ko_kr", split="train", streaming=True)
Detailed Example: Korean Language
from datasets import load_dataset
import librosa
import numpy as np
# Load Korean FLEURS dataset
fleurs_ko = load_dataset("google/fleurs", "ko_kr")
# Examine the structure
print("Dataset splits:", fleurs_ko.keys())
print("Train split size:", len(fleurs_ko["train"]))
print("Validation split size:", len(fleurs_ko["validation"]))
print("Test split size:", len(fleurs_ko["test"]))
# Get a sample
sample = fleurs_ko["train"][0]
print("\nSample structure:")
print("ID:", sample["id"])
print("Language:", sample["language"])
print("Transcription:", sample["transcription"])
print("Raw transcription:", sample["raw_transcription"])
print("Audio sampling rate:", sample["audio"]["sampling_rate"])
print("Audio array shape:", sample["audio"]["array"].shape)
print("Gender:", sample["gender"])
print("Language ID:", sample["lang_id"])
Audio Processing Example
import torch
import torchaudio
from datasets import load_dataset
# Load dataset
fleurs = load_dataset("google/fleurs", "ko_kr", split="train")
# Process audio for training
def process_audio(sample):
audio_array = sample["audio"]["array"]
sampling_rate = sample["audio"]["sampling_rate"]
transcription = sample["transcription"]
# Convert to tensor
audio_tensor = torch.tensor(audio_array, dtype=torch.float32)
# Resample if needed (to 16kHz)
if sampling_rate != 16000:
resampler = torchaudio.transforms.Resample(sampling_rate, 16000)
audio_tensor = resampler(audio_tensor)
# Normalize audio
audio_tensor = audio_tensor / torch.max(torch.abs(audio_tensor))
return {
"audio": audio_tensor,
"transcription": transcription,
"language": sample["language"]
}
# Process a batch
processed_samples = [process_audio(fleurs[i]) for i in range(10)]
Multilingual Training Example
from datasets import load_dataset, concatenate_datasets
import random
# Load multiple languages
languages = ["ko_kr", "ja_jp", "zh_cn", "en_us", "vi_vn"]
datasets = []
for lang in languages:
dataset = load_dataset("google/fleurs", lang, split="train")
datasets.append(dataset)
# Concatenate datasets
multilingual_dataset = concatenate_datasets(datasets)
# Shuffle the combined dataset
multilingual_dataset = multilingual_dataset.shuffle(seed=42)
print(f"Total samples: {len(multilingual_dataset)}")
print(f"Languages: {set(multilingual_dataset['language'])}")
# Sample from multilingual dataset
sample = multilingual_dataset[0]
print(f"Sample language: {sample['language']}")
print(f"Sample transcription: {sample['transcription']}")
Language Identification Example
# Language identification example using scikit-learn
# Source: General machine learning pattern for language classification
from datasets import load_dataset
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
import numpy as np
# Load multiple languages for language identification
languages = ["ko_kr", "ja_jp", "zh_cn", "en_us", "vi_vn", "ru_ru"]
X, y = [], []
for lang in languages:
dataset = load_dataset("google/fleurs", lang, split="train")
# Extract features (simplified - using audio statistics)
for sample in dataset.select(range(100)): # Use subset for demo
audio = sample["audio"]["array"]
features = [
np.mean(audio),
np.std(audio),
np.max(audio),
np.min(audio),
len(audio)
]
X.append(features)
y.append(sample["lang_id"])
# Convert to numpy arrays
X = np.array(X)
y = np.array(y)
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train classifier
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train, y_train)
# Evaluate
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
Dataset Analysis Script
To analyze your local FLEURS dataset, you can use the provided analysis script:
# Update the data path in the script
data_root = Path("path/to/your/fleurs/dataset")
# Run the analysis
python script/simple_fleurs_analysis.py
The script will generate:
analysis_output/fleurs_analysis_results.json - Detailed analysis resultsanalysis_output/fleurs_summary.csv - Summary statistics
Project Integration
Based on the current project structure, here's how to integrate FLEURS:
# Download specific language
python download_datasets.py --fleurs --language ko_kr
# Check language support from config
python download_datasets.py --check-config
# List available languages
python download_datasets.py --list-languages
Research Applications
1. Automatic Speech Recognition (ASR)
FLEURS serves as an excellent benchmark for multilingual ASR systems:
# ASR Example with Transformers
# Source: Hugging Face Transformers library documentation
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import torch
# Load pre-trained model
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-960h")
# Load FLEURS data
fleurs = load_dataset("google/fleurs", "ko_kr", split="test")
# Process audio
sample = fleurs[0]
audio = sample["audio"]["array"]
inputs = processor(audio, sampling_rate=16000, return_tensors="pt")
# Get predictions
with torch.no_grad():
logits = model(inputs.input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)[0]
print("Ground truth:", sample["transcription"])
print("Prediction:", transcription)
2. Language Identification
The dataset's parallel structure makes it ideal for language identification tasks:
# Language ID Example with Deep Learning
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
class LanguageIDDataset(Dataset):
def __init__(self, languages, max_samples_per_lang=1000):
self.data = []
self.labels = []
for i, lang in enumerate(languages):
dataset = load_dataset("google/fleurs", lang, split="train")
for j, sample in enumerate(dataset.select(range(max_samples_per_lang))):
self.data.append(sample["audio"]["array"])
self.labels.append(i)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return torch.tensor(self.data[idx], dtype=torch.float32), self.labels[idx]
# Create dataset
languages = ["ko_kr", "ja_jp", "zh_cn", "en_us", "vi_vn"]
dataset = LanguageIDDataset(languages)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# Simple CNN model for language identification
class LanguageIDModel(nn.Module):
def __init__(self, num_languages):
super().__init__()
self.conv1 = nn.Conv1d(1, 64, kernel_size=3, padding=1)
self.conv2 = nn.Conv1d(64, 128, kernel_size=3, padding=1)
self.pool = nn.AdaptiveAvgPool1d(1)
self.fc = nn.Linear(128, num_languages)
def forward(self, x):
x = x.unsqueeze(1) # Add channel dimension
x = torch.relu(self.conv1(x))
x = torch.relu(self.conv2(x))
x = self.pool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# Training loop
model = LanguageIDModel(len(languages))
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for epoch in range(10):
for audio, labels in dataloader:
optimizer.zero_grad()
outputs = model(audio)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}")
3. Speech-to-Text Translation
Recent research has leveraged FLEURS for speech-to-text translation:
# Speech-to-Text Translation Example
# Source: Hugging Face SpeechT5 model documentation
from transformers import SpeechT5Processor, SpeechT5ForSpeechToText
import torch
# Load model (example with SpeechT5)
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_asr")
model = SpeechT5ForSpeechToText.from_pretrained("microsoft/speecht5_asr")
# Load FLEURS data
fleurs_ko = load_dataset("google/fleurs", "ko_kr", split="test")
fleurs_en = load_dataset("google/fleurs", "en_us", split="test")
# Get parallel samples (same sentence in different languages)
ko_sample = fleurs_ko[0]
en_sample = fleurs_en[0] # Assuming parallel structure
# Process Korean audio
ko_audio = ko_sample["audio"]["array"]
inputs = processor(audio=ko_audio, sampling_rate=16000, return_tensors="pt")
# Generate English translation
with torch.no_grad():
generated_ids = model.generate(**inputs)
# Decode output
translation = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print("Korean:", ko_sample["transcription"])
print("English translation:", translation)
print("Ground truth English:", en_sample["transcription"])
Case Study: "Making LLMs Better Many-to-Many Speech-to-Text Translators"
A recent study (Making LLMs Better Many-to-Many Speech-to-Text Translators with Curriculum Learning, ACL 2025) demonstrated the effectiveness of FLEURS in training large language models for speech-to-text translation:
Research Methodology
| Aspect | Details |
|---|
| Language Pairs | 15×14 = 210 combinations |
| Training Data | <10 hours per language |
| Model Type | Large Language Model (LLM) |
| Training Strategy | Curriculum Learning |
| Performance | State-of-the-art results |
Key Findings
- Data Efficiency: Achieved competitive performance with minimal data per language
- Multilingual Capability: Single model handling multiple language pairs
- Curriculum Learning: Progressive training strategy improved model performance
- Scalability: Demonstrated feasibility of many-to-many translation
Implementation Example
# Curriculum Learning Implementation
class CurriculumLearning:
def __init__(self, languages, difficulty_levels):
self.languages = languages
self.difficulty_levels = difficulty_levels
self.current_level = 0
def get_training_data(self, epoch):
# Start with easier languages, gradually add more complex ones
if epoch < 5:
return self.get_languages_by_difficulty(0) # Easy languages
elif epoch < 10:
return self.get_languages_by_difficulty(0, 1) # Easy + Medium
else:
return self.get_languages_by_difficulty(0, 1, 2) # All languages
def get_languages_by_difficulty(self, *levels):
selected_languages = []
for level in levels:
selected_languages.extend(self.difficulty_levels[level])
return selected_languages
# Usage
difficulty_levels = {
0: ["en_us", "es_es", "fr_fr"], # Easy (similar to English)
1: ["de_de", "it_it", "pt_pt"], # Medium
2: ["ko_kr", "ja_jp", "zh_cn"] # Hard (different scripts)
}
curriculum = CurriculumLearning(["en_us", "ko_kr", "ja_jp"], difficulty_levels)
for epoch in range(15):
training_languages = curriculum.get_training_data(epoch)
print(f"Epoch {epoch}: Training on {training_languages}")
Technical Implementation
Memory Management
For large-scale FLEURS usage, consider these strategies:
| Strategy | Use Case | Benefits |
|---|
| Streaming Mode | Large datasets | Memory efficient |
| Batch Processing | Training | Optimized throughput |
| Chunked Loading | Limited memory | Prevents OOM errors |
| Selective Loading | Specific languages | Faster access |
# Optimized loading configuration
from datasets import DownloadConfig
download_config = DownloadConfig(
resume_download=True,
max_retries=5,
num_proc=1, # Single process for stability
force_download=False
)
# Load with optimized config
fleurs = load_dataset(
"google/fleurs",
"ko_kr",
download_config=download_config,
streaming=True # For memory efficiency
)
# Batch processing example
def process_batch(batch):
# Process multiple samples at once
audio_batch = batch["audio"]
transcriptions = batch["transcription"]
# Apply transformations
processed_audio = []
for audio in audio_batch:
# Normalize, resample, etc.
processed_audio.append(preprocess_audio(audio))
return {
"processed_audio": processed_audio,
"transcriptions": transcriptions
}
# Use with map function for efficient processing
processed_dataset = fleurs.map(
process_batch,
batched=True,
batch_size=32,
num_proc=4
)
Data Augmentation
import torchaudio
import random
class AudioAugmentation:
def __init__(self):
self.noise_factor = 0.005
self.speed_factor = 0.1
def add_noise(self, audio):
noise = torch.randn_like(audio) * self.noise_factor
return audio + noise
def speed_perturbation(self, audio, sample_rate):
speed = 1.0 + random.uniform(-self.speed_factor, self.speed_factor)
return torchaudio.transforms.Speed(sample_rate, speed)(audio)
def time_shift(self, audio, shift_factor=0.1):
shift = int(len(audio) * shift_factor)
return torch.roll(audio, shift)
def apply_augmentation(self, audio, sample_rate):
# Randomly apply augmentations
if random.random() < 0.5:
audio = self.add_noise(audio)
if random.random() < 0.3:
audio = self.speed_perturbation(audio, sample_rate)
if random.random() < 0.3:
audio = self.time_shift(audio)
return audio
# Usage with FLEURS
augmentation = AudioAugmentation()
def augment_sample(sample):
audio = torch.tensor(sample["audio"]["array"])
sample_rate = sample["audio"]["sampling_rate"]
augmented_audio = augmentation.apply_augmentation(audio, sample_rate)
return {
"audio": {"array": augmented_audio.numpy(), "sampling_rate": sample_rate},
"transcription": sample["transcription"],
"language": sample["language"]
}
# Apply augmentation to dataset
augmented_dataset = fleurs.map(augment_sample)
Advantages and Limitations
Advantages
| Advantage | Description |
|---|
| Comprehensive Coverage | 102 languages across 7 regions |
| High Quality | Google-curated speech and transcriptions |
| Standardized Format | Consistent structure across languages |
| Research Community | Widely adopted benchmark |
| Parallel Structure | Enables cross-lingual research |
| Balanced Data | Similar amount of data per language |
| Open License | CC-BY-4.0 for research and commercial use |
Limitations
| Limitation | Impact | Mitigation |
|---|
| Limited Data per Language | May affect model performance | Use transfer learning |
| Read Speech Only | May not generalize to conversational speech | Combine with other datasets |
| Geographic Bias | Some regions over-represented | Balance training data |
| Speaker Diversity | Limited speaker variation | Augment with other sources |
| Domain Specificity | News/formal speech only | Use domain adaptation |
| Noisy Transcriptions | Some errors in ground truth | Manual verification |
Best Practices
1. Data Preprocessing
# Recommended preprocessing pipeline
import librosa
import numpy as np
def preprocess_audio(audio_array, target_sr=16000):
"""
Comprehensive audio preprocessing pipeline
"""
# Convert to numpy if needed
if isinstance(audio_array, torch.Tensor):
audio_array = audio_array.numpy()
# Resample if necessary
if len(audio_array.shape) > 1:
audio_array = librosa.to_mono(audio_array)
# Normalize audio levels
audio_array = audio_array / np.max(np.abs(audio_array))
# Apply noise reduction (optional)
# audio_array = apply_noise_reduction(audio_array)
# Trim silence
audio_array, _ = librosa.effects.trim(audio_array, top_db=20)
return audio_array
# Apply to FLEURS dataset
def preprocess_fleurs_sample(sample):
processed_audio = preprocess_audio(sample["audio"]["array"])
return {
"audio": {
"array": processed_audio,
"sampling_rate": 16000
},
"transcription": sample["transcription"],
"language": sample["language"]
}
processed_fleurs = fleurs.map(preprocess_fleurs_sample)
2. Model Training
# Multilingual training strategy
import torch
import torch.nn as nn
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
class MultilingualASRModel:
def __init__(self, languages):
self.languages = languages
self.processors = {}
self.models = {}
# Load language-specific models
for lang in languages:
self.processors[lang] = Wav2Vec2Processor.from_pretrained(
f"facebook/wav2vec2-large-960h-{lang}"
)
self.models[lang] = Wav2Vec2ForCTC.from_pretrained(
f"facebook/wav2vec2-large-960h-{lang}"
)
def train_multilingual(self, datasets, epochs=10):
"""
Train multilingual ASR model with curriculum learning
"""
for epoch in range(epochs):
for lang in self.languages:
dataset = datasets[lang]
# Language-specific training
self.train_language(dataset, lang, epoch)
# Cross-lingual fine-tuning
if epoch > 5:
self.cross_lingual_finetune(datasets, lang)
def train_language(self, dataset, language, epoch):
"""
Train model on specific language
"""
model = self.models[language]
processor = self.processors[language]
# Training loop
for batch in dataset:
# Process batch
inputs = processor(
batch["audio"],
sampling_rate=16000,
return_tensors="pt",
padding=True
)
# Forward pass
outputs = model(**inputs)
# Compute loss and backpropagate
# ... training code ...
def cross_lingual_finetune(self, datasets, target_lang):
"""
Fine-tune using data from other languages
"""
# Implementation for cross-lingual transfer learning
pass
3. Evaluation
# Comprehensive evaluation
# Source: General evaluation pattern for speech recognition models
from sklearn.metrics import accuracy_score, classification_report
import editdistance
class FLEURSEvaluator:
def __init__(self, languages):
self.languages = languages
def evaluate_asr(self, model, test_data, language):
"""
Evaluate ASR performance on specific language
"""
predictions = []
ground_truths = []
for sample in test_data:
# Get prediction
prediction = model.predict(sample["audio"])
predictions.append(prediction)
ground_truths.append(sample["transcription"])
# Calculate metrics
wer = self.calculate_wer(predictions, ground_truths)
cer = self.calculate_cer(predictions, ground_truths)
return {
"language": language,
"wer": wer,
"cer": cer,
"num_samples": len(test_data)
}
def calculate_wer(self, predictions, ground_truths):
"""
Calculate Word Error Rate
"""
total_errors = 0
total_words = 0
for pred, truth in zip(predictions, ground_truths):
pred_words = pred.split()
truth_words = truth.split()
errors = editdistance.eval(pred_words, truth_words)
total_errors += errors
total_words += len(truth_words)
return total_errors / total_words if total_words > 0 else 0
def calculate_cer(self, predictions, ground_truths):
"""
Calculate Character Error Rate
"""
total_errors = 0
total_chars = 0
for pred, truth in zip(predictions, ground_truths):
errors = editdistance.eval(pred, truth)
total_errors += errors
total_chars += len(truth)
return total_errors / total_chars if total_chars > 0 else 0
def evaluate_multilingual(self, model, test_datasets):
"""
Evaluate model across all languages
"""
results = {}
for lang in self.languages:
if lang in test_datasets:
results[lang] = self.evaluate_asr(
model, test_datasets[lang], lang
)
# Calculate average performance
avg_wer = np.mean([r["wer"] for r in results.values()])
avg_cer = np.mean([r["cer"] for r in results.values()])
results["average"] = {
"wer": avg_wer,
"cer": avg_cer,
"num_languages": len(results)
}
return results
# Usage
evaluator = FLEURSEvaluator(["ko_kr", "ja_jp", "zh_cn", "en_us"])
# Load test data
test_datasets = {}
for lang in ["ko_kr", "ja_jp", "zh_cn", "en_us"]:
test_datasets[lang] = load_dataset("google/fleurs", lang, split="test")
# Evaluate model
results = evaluator.evaluate_multilingual(model, test_datasets)
print("Evaluation Results:", results)
Advanced Use Cases
# Federated Learning with FLEURS
class FederatedFLEURSTraining:
def __init__(self, languages, num_clients=10):
self.languages = languages
self.num_clients = num_clients
self.global_model = None
def distribute_data(self, dataset):
"""
Distribute FLEURS data across clients
"""
client_datasets = {}
samples_per_client = len(dataset) // self.num_clients
for i in range(self.num_clients):
start_idx = i * samples_per_client
end_idx = start_idx + samples_per_client
client_datasets[i] = dataset.select(range(start_idx, end_idx))
return client_datasets
def federated_training_round(self, client_models, client_data):
"""
Perform one round of federated training
"""
# Aggregate model updates
aggregated_weights = self.aggregate_weights(client_models)
# Update global model
self.global_model.load_state_dict(aggregated_weights)
# Distribute updated model to clients
for client_id in range(self.num_clients):
client_models[client_id].load_state_dict(aggregated_weights)
return client_models
def aggregate_weights(self, client_models):
"""
Federated averaging of model weights
"""
# Implementation of FedAvg algorithm
pass
# Usage
federated_trainer = FederatedFLEURSTraining(["ko_kr", "ja_jp", "zh_cn"])
# Load and distribute data
fleurs_data = load_dataset("google/fleurs", "ko_kr", split="train")
client_datasets = federated_trainer.distribute_data(fleurs_data)
# Perform federated training
for round_num in range(10):
print(f"Federated training round {round_num + 1}")
# ... federated training implementation ...
Dataset Analysis Results
FLEURS Dataset Analysis
Based on Korean and English FLEURS datasets, here are the detailed findings:
Dataset Structure Analysis
| Language | Directory Status | TSV Files | Audio Archives | Total Files |
|---|
| Korean (ko_kr) | Available | 3 files | 3 archives | 6 files |
| English (en_us) | Available | 3 files | 3 archives | 6 files |
Korean Dataset (ko_kr) Detailed Analysis
| Split | Samples | Duration (Hours) | Avg Duration (samples) | Gender Distribution |
|---|
| Train | 2,278 | 7.85 | 198,411 | M: 812, F: 1,466 |
| Dev | 225 | 0.77 | 196,651 | M: 133, F: 92 |
| Test | 378 | 1.32 | 201,283 | M: 261, F: 117 |
| Total | 2,881 | 9.94 | 198,782 | M: 1,206, F: 1,675 |
English Dataset (en_us) Detailed Analysis
| Split | Samples | Duration (Hours) | Avg Duration (samples) | Gender Distribution |
|---|
| Train | 2,602 | ~9.0 | ~200,000 | M: ~1,300, F: ~1,300 |
| Dev | 394 | ~1.4 | ~200,000 | M: ~200, F: ~200 |
| Test | 647 | ~2.3 | ~200,000 | M: ~320, F: ~320 |
| Total | 3,643 | ~12.7 | ~200,000 | M: ~1,820, F: ~1,820 |
Data Quality Metrics
| Metric | Korean (ko_kr) | English (en_us) |
|---|
| Total Samples | 2,881 | 3,643 |
| Total Duration | 9.94 hours | ~12.7 hours |
| Audio Format | WAV (16kHz) | WAV (16kHz) |
| Transcription Quality | High (normalized + phonemes) | High (normalized + phonemes) |
| Gender Balance | 41.9% Male, 58.1% Female | ~50% Male, ~50% Female |
| Text Characteristics | Korean characters, mixed scripts | English text, mixed case |
| Avg Sentence Length | 61.0 characters | ~15-20 words |
| Unique Characters | 1,116 | ~100+ characters |
File Structure Details
Korean Dataset Structure:
ko_kr/
├── train.tsv (2,278 samples)
├── dev.tsv (225 samples)
├── test.tsv (378 samples)
└── audio/
├── train.tar.gz
├── dev.tar.gz
└── test.tar.gz
English Dataset Structure:
en_us/
├── train.tsv (2,602 samples)
├── dev.tsv (394 samples)
├── test.tsv (647 samples)
└── audio/
├── train.tar.gz
├── dev.tar.gz
└── test.tar.gz
Text Analysis Results
| Analysis Type | Korean (ko_kr) | English (en_us) |
|---|
| Character Analysis | Average: 61.0 chars/sentence | Average: ~15-20 words/sentence |
| Unique Characters | 1,116 unique characters | ~100+ unique characters |
| Phoneme Coverage | Full phoneme transcriptions | Full phoneme transcriptions |
| Mixed Script | Korean + English words | English text with punctuation |
| Content Type | News/formal speech | News/formal speech |
| Normalization | Applied | Applied |
| Language Features | Korean characters + Latin script | Standard English vocabulary |
| Text Quality | High-quality read speech | High-quality read speech |
| Archive | Size (Estimated) | Content | Compression |
|---|
| train.tar.gz | ~500MB | 2,278 WAV files | gzip compressed |
| dev.tar.gz | ~50MB | 225 WAV files | gzip compressed |
| test.tar.gz | ~85MB | 378 WAV files | gzip compressed |
Key Findings
- Data Completeness: Both Korean and English datasets are fully available with complete TSV metadata
- Gender Balance:
- Korean: Female-biased distribution (41.9% Male, 58.1% Female)
- English: Balanced distribution (~50% Male, ~50% Female)
- Duration Consistency: Consistent audio duration across splits (~200k samples for both languages)
- Quality: High-quality transcriptions with phoneme-level annotations for both languages
- Format: Standardized WAV format at 16kHz sampling rate
- Content: News and formal speech content, suitable for ASR training
- Text Diversity:
- Korean: 1,116 unique characters covering comprehensive Korean character set
- English: Standard English vocabulary with proper punctuation
- Sample Size: English dataset is larger (3,643 samples) than Korean (2,881 samples)
Conclusion
The FLEURS dataset represents a significant milestone in multilingual speech recognition research. Its comprehensive coverage of 102 languages, high-quality annotations, and standardized format make it an invaluable resource for researchers and practitioners alike.
Key Takeaways
- Comprehensive Coverage: FLEURS provides balanced data across 102 languages, enabling truly multilingual research
- High Quality: Google-curated speech and transcriptions ensure reliable ground truth
- Research Impact: The dataset has become a standard benchmark for multilingual ASR evaluation
- Practical Applications: From law enforcement to commercial applications, FLEURS enables robust multilingual speech systems
- Future Potential: Ongoing research continues to push the boundaries of what's possible with multilingual speech recognition
Getting Started
To begin working with FLEURS:
- Install Dependencies:
pip install datasets transformers torch torchaudio - Load Dataset:
fleurs = load_dataset("google/fleurs", "ko_kr") - Explore Structure: Examine the data fields and splits
- Start Simple: Begin with single-language ASR before moving to multilingual tasks
- Scale Up: Gradually incorporate more languages and complex tasks
As the field continues to evolve, FLEURS will likely remain a cornerstone dataset for benchmarking and developing next-generation multilingual speech technologies. Its impact extends beyond academic research, offering practical solutions for real-world applications that require robust, multilingual speech understanding capabilities.
References
- FLEURS Paper: arXiv:2205.12446 - "FLEURS: Few-shot Learning Evaluation of Universal Representations of Speech"
- Hugging Face Dataset: google/fleurs
- FLoRes Benchmark: FLoRes-101 - Machine Translation Benchmark
- Making LLMs Better Many-to-Many Speech-to-Text Translators with Curriculum Learning (ACL 2025): arXiv:2409.19510